
Ein Datenmodell über alle Instanzen zu erstellen, bedarf einer Höchstleistung für alle Datenmodellierer. Disziplin, Perfektion, Agilität, Ausdauer und ein exzellentes Domain Wissen sind das A und O eines jeden Datenmodellierers. Dieser Blogbeitrag gibt einen Einblick in die Welt der Datenmodellierung und zeigt anhand von einem Beispiel auf, was es alles zu beachten gibt.
Die Hauptzutaten für ein erfolgreiches Datenmodell Gericht bestehen aus Business Domain Wissen und analytischen Fähigkeiten. Diese werden im konzeptionellen Topf gegart und mit einer scharfen Prise Sourcing, Stagging, Cleansing, Processing und Distribution gewürzt. Danach kippt man alles in den logischen Topf um und schüttet reichlich Entitäten, Objekte und Elemente dazu. Das ganze Gericht wird am Ende im physischen Topf schliesslich mit der «Single Source of Truth» veredelt.
Fertig ist das Gault Millau Datenmodell Gericht. Ready to serve, or not?
Ein Datenmodell dient einzig und allein dem Zweck, den Entscheidungsträger zu unterstützen.
Was ist ein Datenmodell?
Ein Datenmodell organisiert und standardisiert Daten und deren Beziehungen in einer grafischen Darstellung zueinander. Datenmodelle dienen zum besseren Verständnis von Geschäftsprozessen und vereinfachen die Kommunikation zwischen dem Business und der Informatik. Wir unterscheiden im Wesentlichen drei Arten von Datenmodellen.
Das konzeptionelle Datenmodell wird entwickelt, um komplexe Geschäftsprozesse oder strategische Datenprojekte möglichst einfach darzustellen. Es bildet eine reine Fachlichkeit ab und ist unabhängig jeglicher technischen Umsetzung. Vor allem Fachkräfte und Product Owner lieben diese Welt des Domain Wissens.
Das logisches Datenmodell bildet das konzeptionelle Datenmodel als eine abstrakte Struktur dar. Die Realität ist in Elemente, Objekte und Entitäten, samt aller relevanten Details wiedergegeben. Geschäftsprozesse werden modelliert und auf die zu verwendenden Datenbanksysteme übertragen. Unverarbeitete Daten sind hier das Paradies für Data Scientists und Business Analysten.
Das physisches Datenmodell erweitert das logische Datenmodell mit allen dazugehörenden technischen Aspekten und Regelwerken. Data Governance sorgt dafür, dass die Datenintegrität, -redundanz und Datenschutz als «Single Source of Truth» jederzeit gewährleistet und sichergestellt ist. Data Engineers und IT-Entwickler sind hier besonders gefordert.

Werden wir konkret und schauen uns ein Beispiel an. Ein Product Owner kontaktiert uns mit der Anforderung: «Für die Portfoliobewertung benötigen wir tägliche Börsenkurse für unsere Investments». Wir fragen nach: «Ok gut; und was sonst noch?» Bereits bei dieser Nachfrage schaut mich mein Gegenüber fragend an. Sicher ist dieses Szenario etwas übertrieben, aber es veranschaulicht, wie wichtig das Domain Wissen bei der Datenmodellierung ist.
Nehmen wir für unser Beispiel eine Schweizer Aktie, die an mehreren Börsen weltweit in verschiedenen Währungen gehandelt wird.
Auf die Begrifflichkeiten Kosten, technische Umsetzungen (physisches Datenmodell) und Data Warehouse oder Data Lakes geht dieser Blog nicht ein.
| Domain Wissen ist die Grundlage jeglicher Datenmodellierung.
Visualisierung und konzeptionelle Darstellung
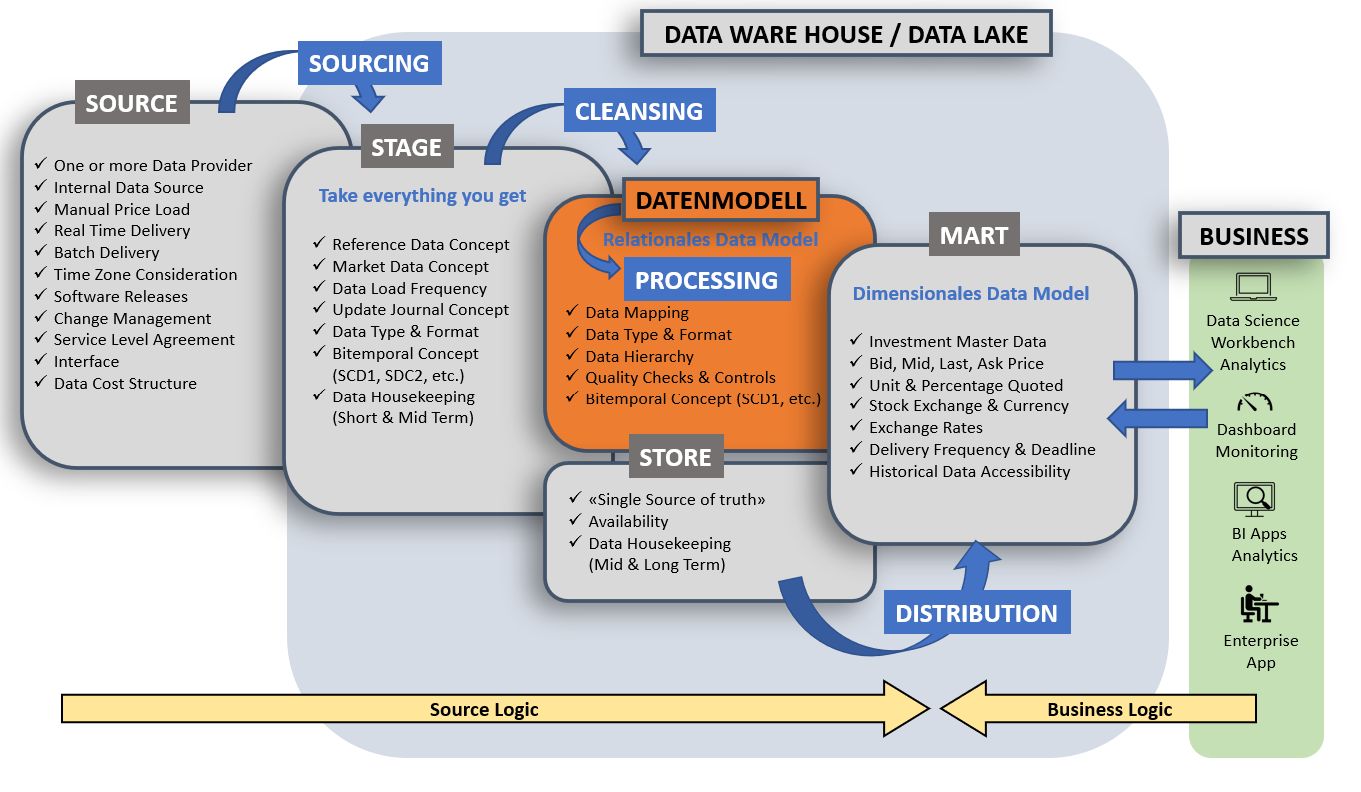
Die folgenden Bilder sind nicht vollständig, verdeutlichen aber die Komplexität einer einzigen Anforderung. Zuerst unterteilen wir alle Aspekte, die sich aus der Anforderung ergeben oder ergeben können, in die Bereiche Source, Stage, Store und Mart ein. Das ermöglicht einen ersten Einblick in die entstehenden Hot Topics, die es schnellstmöglich zu initiieren gilt. So zum Beispiel die Source, denn ohne Daten kein Business Intelligence!
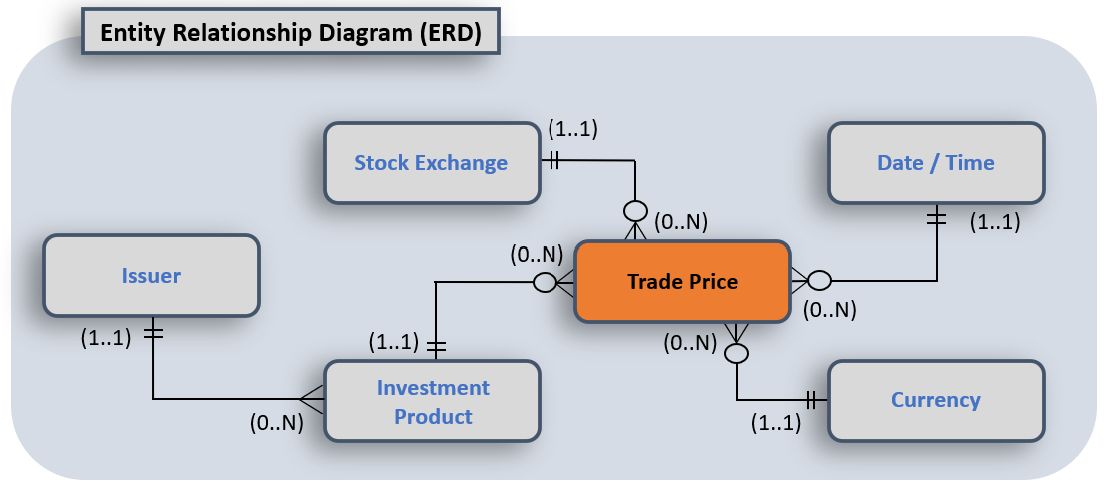
Nun beginnt die Erstellung des Entitäten-Beziehungs-Diagramm. Folgendes Bild zeigt ein Beispiel einer Beziehung zwischen dem gehandelten Aktienpreis und seinen Entitäten.
Innerhalb der konzeptionellen Phase entwickeln sich meist mehrere Varianten. Für die Anforderung «Für die Portfoliobewertung benötigen wir tägliche Börsenkurse für unsere Investments» entscheiden wir uns für Variante 1.
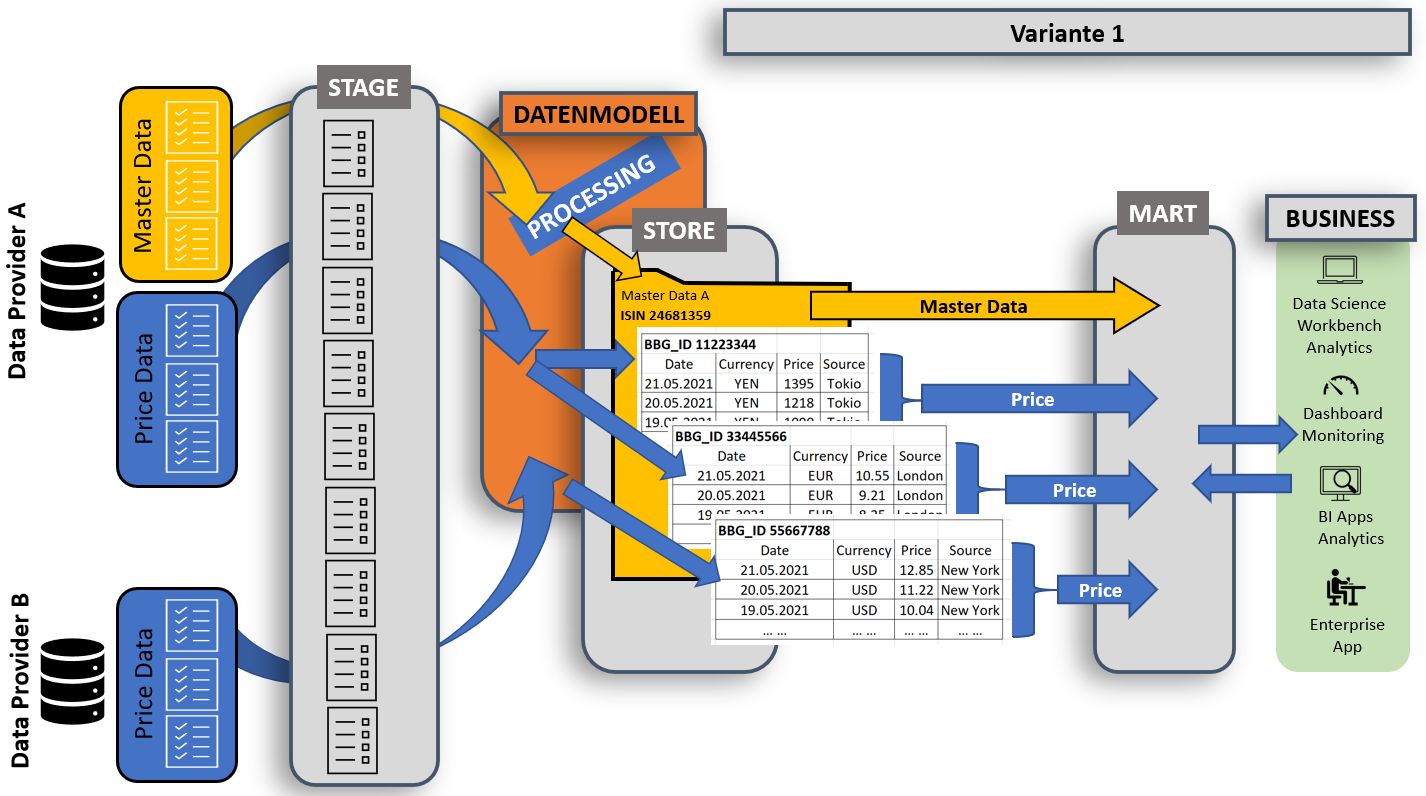
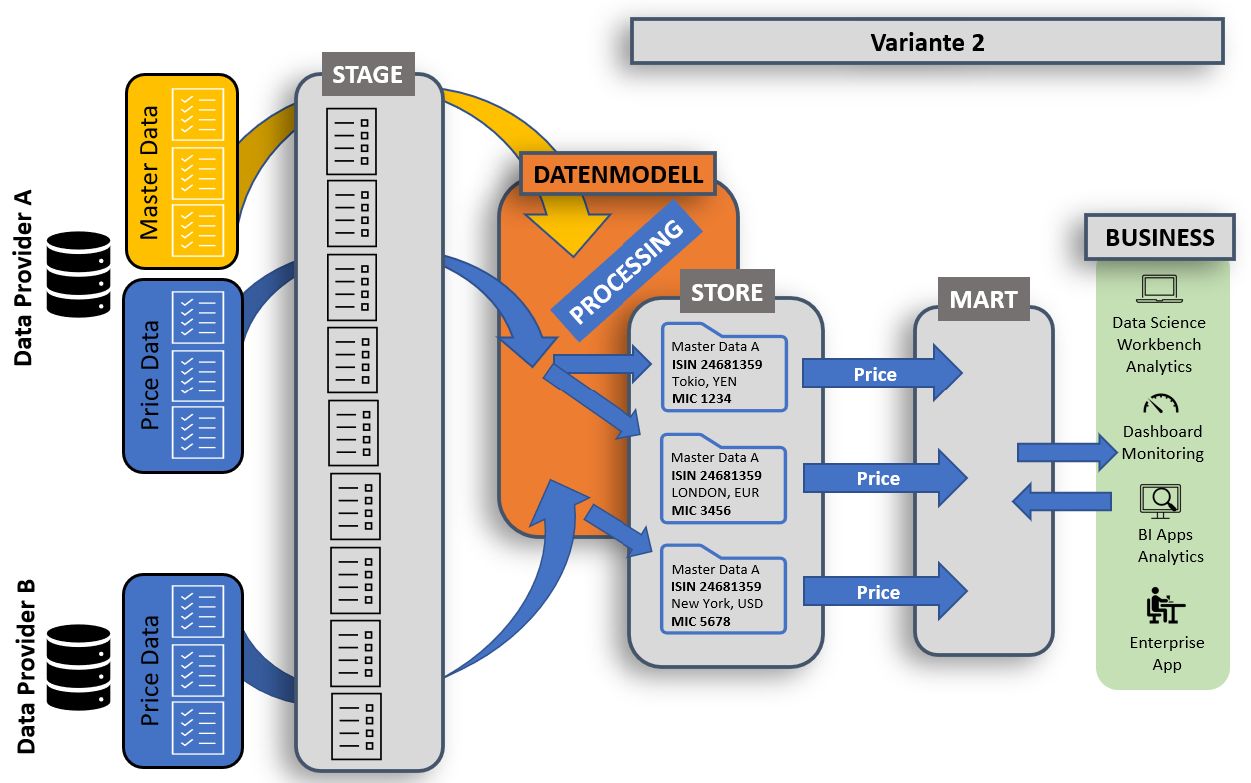
Spätestens hier verstehen alle Beteiligten den Geschäftsprozess. Dieser ist eindeutig und verständlich als Spezifikation niedergeschrieben. Ein Sing-off von allen Beteiligten ist jetzt zwingend.
Die logische Datenmodellierung
Ab hier kennt die Abstraktivität keine Grenzen mehr. Es existieren keine Rezepte für das perfekte logische Gault Millau Datenmodell Gericht. Eines ist aber für alle gleich. Das logische Datenmodell benötigt viel Disziplin, Perfektion und Ausdauer. Oder auch Liebe fürs Detail. Wichtig: Es ist erforderlich, ja sogar zwingend, das Datenmodell ohne Zeitverzug auf dem neusten Stand zu halten.

Erfolgreiche Datenmodelle bestechen durch Datenintegrität und -redundanz.
Das alles für eine einzige Anforderung? Jawohl.
Ein Gault Millau Gericht besteht aus vielen einzelnen Zutaten, die sorgfältig und zur richtigen Zeit miteinander vermischt werden. Es ist das Bestreben aller Beteiligten jeden einzelnen End-to-End Geschäftsprozess zu verstehen und diesen einfach und effizient in die digitale Transformation umzusetzen.
Weiterführende Links: