
Microservices, die Heilsbringer der modernen Softwareentwicklung, bringen uns Skalierbarkeit, Unabhängigkeit, Vielfalt, Wartbarkeit, aber auch Chaos in die ehemals eher starren Strukturen der DevOps. Wie behalten wir die Übersicht über unsere Services und wer informiert uns, sobald etwas nicht mehr so läuft wie es sollte?
In der stetig komplexer werdenden Welt der Softwareentwicklung ist ein effizientes Application Monitoring von entscheidender Bedeutung, um die Leistung, Verfügbarkeit und Zuverlässigkeit von Anwendungen sicherzustellen. Ein leistungsstarkes Werkzeug, welches in diesem Zusammenhang immer mehr an Bedeutung gewinnt, ist Prometheus.
Ursprünglich von den Machern von SoundCloud entwickelt und nun als unabhängiges OpenSource Projekt verfügbar, ist Prometheus ein unverzichtbarer Besandteil vieler DevOps-Umgebungen geworden und hilft dabei, umfassende Metriken zu sammeln, Alarme zu setzen und Einblicke in die Gesundheit von Anwendungen zu liefern.
Wie funktioniert Prometheus?
Prometheus nutzt, wie für diesen UseCase üblich, eine TimeSeries Datenbank. Mit der Abfragesprache „PromQL“ können Entwickler und Betriebsteams tiefgehende Einblicke in die Leistung ihrer Anwendungen gewinnen. Die Flexibilität von Prometheus ermöglicht es, verschiedene Datenquellen, sogenante Targets, zu integrieren und benutzerdefinierte Dashboards zu erstellen.
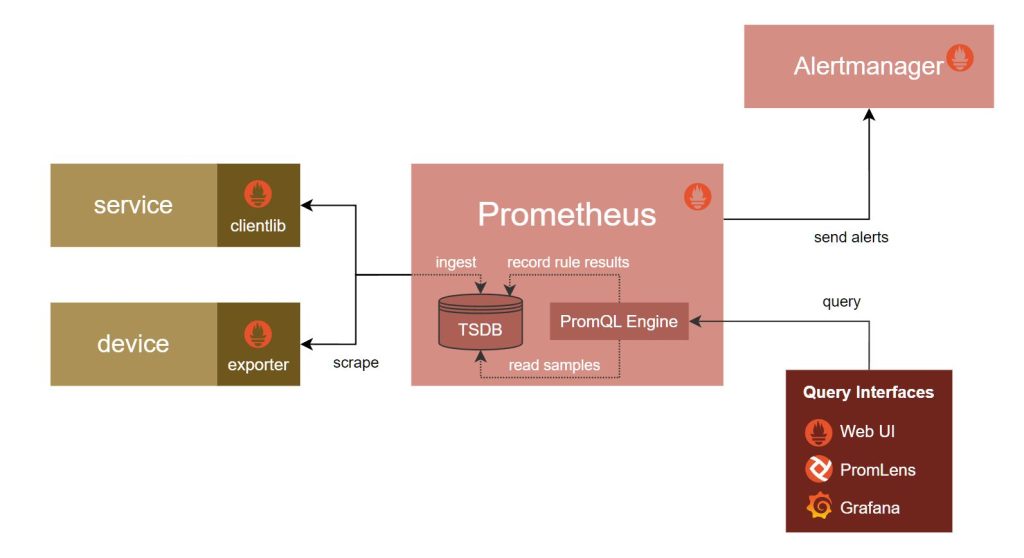
Wie überwache ich nun meine Services?
Für Prometheus existieren diverse client libraries, welche einem die Integration vereinfachen. Wichtig ist, dass deine Services einen HTTP Endpunkt zur Verfügung stellen, über den die Daten bezogen werden können.
Und Container überwachen?
Mit Hilfe des von Google entwickelten cAdvisor lassen sich der Ressourcenverbrauch und die Performance Charakteristiken von laufenden Containern ermitteln.
Zuerst wird das Target in prometheus.yml definiert.
scrape_configs: - job_name: cadvisor scrape_interval: 5s static_configs: - targets: - cadvisor:8080
Danach wird cAdvisor als Service ergänzt und konfiguriert.
Hier ein Beispiel Service Stack, um ein Redis Service zu überwachen. Die vorhin angelegte prometheus.yml wird als Konfigurationsfile eingelesen.
version: '3.2' services: prometheus: image: prom/prometheus:latest container_name: prometheus ports: - 9090:9090 command: - --config.file=/etc/prometheus/prometheus.yml volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml:ro depends_on: - cadvisor cadvisor: image: gcr.io/cadvisor/cadvisor:latest container_name: cadvisor ports: - 8080:8080 volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro depends_on: - redis redis: image: redis:latest container_name: redis ports: - 6379:6379
Nun kann der Service Stack wie gewohnt über den Befehl docker compose up gestartet werden.
Unter http://localhost:9090/graph erreichen wir den Prometheus Expression Browser. Dort können wir aktuelle Informationen zu den laufenden Containern abfragen. Zum Beispiel gibt uns container_memory_working_set_bytes{name=“redis“} die aktuelle Memory Last in bytes an.
Was messe ich alles?
Mit einem soliden Tool im Rücken, stellt sich nun die Frage, welche Metriken nun überwacht werden sollen. Am besten ALLE!? Doch alle möglichen Metriken zu tracken verursacht zum einen Aufwand und zum anderen wieder Chaos durch Unübersichtlichkeit. Am Besten startet man mit den 4 Golden Signals.
„The four golden signals of monitoring are latency, traffic, errors, and saturation. If you can only measure four metrics of your user-facing system, focus on these four.“
Monitoring Distributed Systems – by Rob Ewaschuk & Betsy Beyer
- Latenz
Wie lange braucht eine Anwendung, um eine Anfrage zu beantworten. Hierbei ist es wichtig, zwischen erfolgreichen und fehlgeschlagenen Anfragen zu unterscheiden. - Verkehr
Wie viele Anfragen erhält eine Anwendung über einen gegebenen Zeitraum? - Fehler
Wie oft antwortet die Anwendung mit einem Fehler? - Auslastung
Wie viel der zur Verfügung stehenden Ressourcen (CPU, RAM, Speicher) sind noch frei? Beschränke dich auf die relevanteste Ressource.
Wie weiter?
Nun, da wir die Daten in Prometheus zentral gespeichert haben, bieten sich uns zahlreiche weitere Möglichkeiten, wie wir sie weiter nutzen können.
- Man könnte Alarme über den AlertManager einrichten und uns via Mails, Webhooks oder über sonstige Wege benachrichtigen lassen.
- Man könnte Grafana als Visualisierungstool in den Stack aufnehmen und ein Dashboard anlegen.
- Man könnte aggregierte Werte in den Data Lake exportieren, um Verbindungen zwischen System- & Revenue Performance herzustellen.
Weiterführende Links zum Thema
Installationsanleitung cAdvisor
Prometheus Alternativen (InfluxDB, Sensu, Graphite, Nagios)