
Wer regelmässig im Internet unterwegs ist, ist ihnen bestimmt schon begegnet: CAPTCHAs. Testaufgaben, die sicherstellen sollen, dass sich hinter dem Benutzer ein Mensch und keine Maschine verbirgt. Doch dies ist nur die halbe Wahrheit – wie diese Aufgaben zur Datengewinnung genutzt werden und wieso dies hilft selbstfahrende Autos sicherer zu machen, erfährst du hier!
CAPTCHAs («completely automated public Turing test to tell computers and humans apart») dienen als zusätzliche Sicherheitsbarriere um Websites vor Missbrauch durch nicht menschliche Benutzer, so genannte Bots, zu schützen.
Google hat mit «reCAPTCHA» eines der bekanntesten CAPTCHA-Systeme geschaffen. In der dazugehörigen Dokumentation findet man jedoch auch folgende Aussage, welche zeigt, dass dieses System nicht rein zu Sicherheitszwecken verwendet wird:
„reCAPTCHA offers more than just spam protection. Every time our CAPTCHAs are solved, that human effort helps digitize text, annotate images, and build machine learning datasets. This in turn helps preserve books, improve maps, and solve hard AI problems.“
Doch was hat das mit selbstfahrenden Autos zu tun? Um diese Frage beantworten zu können, müssen wir uns zuerst mit den Grundlagen der künstlichen Intelligenz befassen.
Wie Maschinen lernen
Das Feld, das sich mit der Erarbeitung von Algorithmen beschäftigt, die in der Lage sind komplexe Aufgaben zu lösen, wird als Machine Learning bezeichnet. Die dabei eingesetzten Modelle haben die Fähigkeit aus Daten zu lernen und das Gelernte auf eine neue Ausgangslage anzuwenden, ohne dass eine menschliche Intervention nötig ist. Daher werden solche Algorithmen auch als künstliche Intelligenz bezeichnet.
Was das genau bedeutet lässt sich am besten anhand eines Beispiels erläutern:
Nehmen wir an die Aufgabe besteht darin Bilder von Hunden und Katzen korrekt zu klassifizieren, sprich unser Machine Learning Modell soll die Bilder der jeweils richtigen Kategorie zuordnen.
Neben einem passenden Machine Learning Algorithmus (eine Übersicht findest du hier) brauchen wir Trainingsbilder damit unser Algorithmus lernt, Hunde und Katzen anhand von Merkmalen, in diesem Kontext Features genannt, zu unterscheiden:
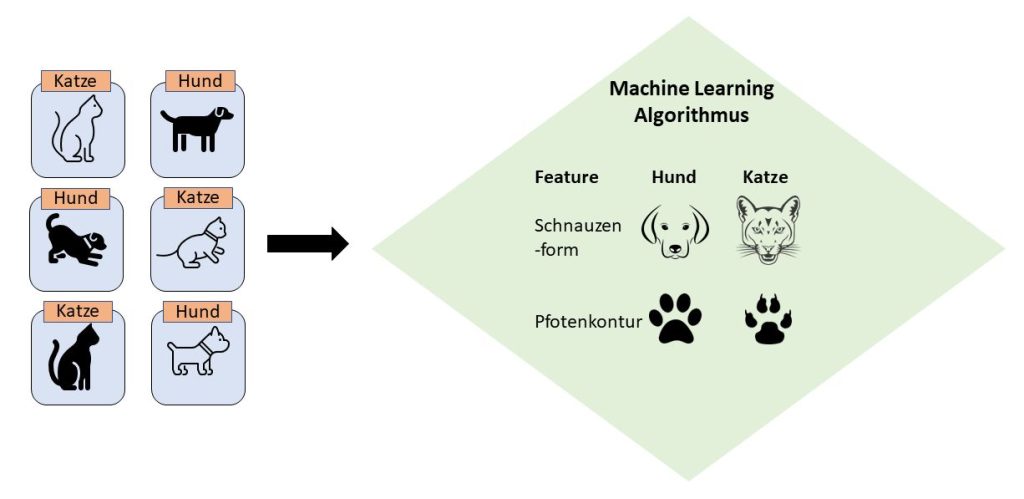
Die Features in unserem Beispiel sind eine starke Vereinfachung davon, was ein solcher Algorithmus für die Unterscheidung verschiedener Klassen brauchen kann. Hier findest du einige Beispiele für Features in verschiedenen Einsatzfeldern von Machine Learning Algorithmen. Im klassischen Machine Learning werden die Features vom Menschen definiert. Es gibt jedoch auch Algorithmen, welche die relevanten Features selbst erkennen und somit noch weniger menschliche Interaktion benötigen – diese findet man in der Kategorie der Deep Learning Algorithmen.
Das Training eines Machine Learning Modells kann je nach Komplexität und Grösse des Trainingsdatensets von wenigen Minuten bis hin zu mehreren Wochen dauern. Nachdem das Training erfolgreich beendet wurde, ist der Algorithmus in der Lage Hunde und Katzen auf neuen Bildern voneinander zu unterscheiden und den Bildern die korrekten Labels zuzuweisen:
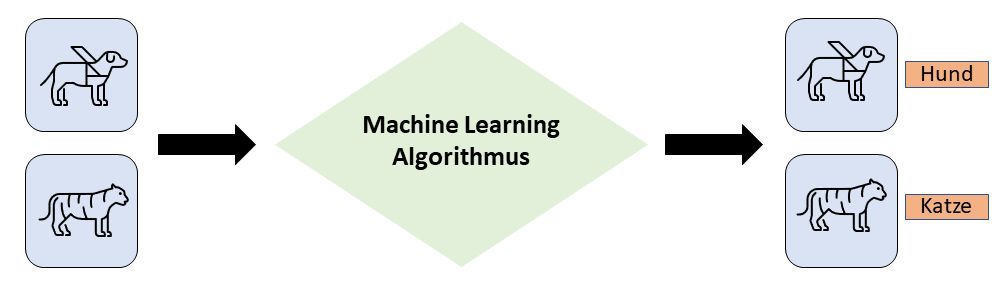
Für komplexe Aufgaben werden mehrere Tausend bis Millionen von Trainingsdaten benötigt. Grundsätzlich gilt: Je mehr Trainingsdaten, desto besser kann der Algorithmus lernen. All diesen Daten ein korrektes Label zu verpassen nimmt sehr viel Zeit in Anspruch – und genau hier profitiert Google von den CAPTCHAs!
Was hat es denn nun mit den selbstfahrenden Autos auf sich?
Ein Beispiel: Ein CAPTCHA zeigt eine Auswahl von neun Bildern – bei acht davon kennt Google bereits das richtige Label. Die Aufgabe für den Benutzer besteht nun darin, alle Bilder zu markieren, welche ein gelbes Auto zeigen. Wird das noch unbekannte Bild im Zuge der Aufgabe ebenfalls markiert, erhält Google die Information, dass dieses Bild ein gelbes Auto zeigt und kann ihm dementsprechend ein Label zuordnen.
Oftmals zeigen CAPTCHAs Bilder von Strassen, Autos oder Verkehrszeichen, welche zum Beispiel als Trainingsdaten für Modelle zur Objekterkennung im Strassenverkehr dienen könnten. Da Google mit WAYMO über ein eigenes „Self-Driving-Car“-Projekt verfügt, ist es naheliegend, dass ein Grossteil der von uns gelabelten Bilder unter anderem dafür genutzt wird.
Somit leisten wir alle einen Beitrag zur Verbesserung der Technologie, die für die Sicherheit auf unseren Strassen einen immer grösser werdenden Stellenwert hat!