
Was charakterisiert BigData und wie können traditionelle ETL-Architekturen in moderne Datenplattformen integriert werden? – Dieser Blogbeitrag soll helfen, BigData als Wortlaut in den richtigen Kontext zu bringen, Anwendungsfälle daraus abzuleiten und aufzeigen, wie Batch- und Realtime-Architekturen in modernen Datenplattformen vereint werden können.
BigData, ein Wort hinter welchem mehr als «grosse Daten» steckt. In der Fachwelt spricht man im Zusammenhang mit BigData von sogenannten V’s. Angelehnt an die Definition von IBM wird BigData durch die Kombination «Volume», «Velocity», «Variety» und «Veracity» charakterisiert. Es gibt auch Quellen, welche zusätzliche Kriterien wie «Value» und «Visibility» beinhalten, wobei ich persönlich die 4V-Charakteristik am zutreffendsten empfinge, da betriebswirtschaftlich betrachtet sowieso jede Unternehmenstätigkeit früher oder später einen Value erbringen muss, um existenzberechtigt zu sein.
Aber was bedeuten die 4V’s konkret?
Volume: Ununterbrochen werden im Internet riesige Datenmengen generiert und konsumiert. Das stetige Datenwachstum beispielsweise durch Sensoren aus der IoT-Welt, unser Bedürfnis nach Vernetzung auf sozialen Medien, das Online-Shopping oder der Audio- und Video-Konsum über Streamingdiensten wie Spotify oder Netflix begleiten uns Tag für Tag und sind nur einige Beispiele für Volume. So beinhaltete gemäss allaccess eine Internetminute im Jahr 2021 beispielsweise 69 Mio. Nachrichten über Metas WhatsApp- und Messenger-Plattformen, 414’764 App-Downloads über den Apple- und Google Play-Store, den Upload von 500 Stunden YouTube-Inhalten, 197,6 Mio. gesendete Emails, $ 1,6 Mio. Online-Einkäufe, 200’000 Tweets oder 9’132 Verbindungen auf Linkedin – und das Minute für Minute!

Eine Internetminute im Jahr 2021 (Quelle: allaccess, online)
Velocity oder «data in motion» charakterisieren beispielsweise IoT-Sensordaten einer Wetterstation, welche nicht auf dieser gespeichert, sondern kontinuierliche erzeugt und versendet werden. Ein weiteres Beispiel ist das streamen eines Netflix-Films, welcher nicht als Ganzes, sondern schnippselweise und fortlaufend von unserem Gerät empfangen und wieder gelöscht wird. Die Daten sind also in ständiger Bewegung.
Variety beschreibt die Vielfalt der Datenquellen und Formate. So werden heute Modelle und Algorithmen entwickelt, welche Quellen- und Formübergreifende Strukturen erkennen und interpretieren verhelfen. Analysen von strukturierten Daten, wie sie in relationalen Datenbanken oder Excel-Tabellen vorkommen, über halbstrukturierte Daten wie XML oder JSON, bis hin zu unstrukturierten Daten, wie beispielsweise Tweets, Mails, Protokolle, Bilder, Audio- oder Videodaten sind kaum Grenzen gesetzt.
Veracity charakterisiert die Wahrhaftigkeit der Daten und somit indirekt deren Qualität. Es erstaunt nicht, dass Veracity in den letzten Jahren stark an Bedeutung zugenommen hat, denn neben unvollständigen oder nicht aktuellen Daten spielt auch die Mehrdeutigkeit oder gar Falschaussagen, beispielsweise in Form von Fake-News, eine zentrale Rolle.
Das hohe Datenvolumen, die tiefe Granularität der Rohdaten sowie unterschiedliche Datenquellen und- Strukturen sind nur einige Eigenschaften um daraus zukunftsgerichtete Use-Cases und Datenanalysemöglichkeiten abzuleiten. Bill Inmon, welcher auch als „Vater des Datawarehousing“ gillt, erklärt in einem Interview mit databricks die unterschiedlichen Sichtweise zwischen Endbenutzer, welche sich an KPIs orientieren um operative oder strategische Entscheidungen zu treffen und DataScientisten, welche in den Daten nach Muster suchen, um Trends frühzeitig zu erkennen, Datenhistorien versuchen zu verstehen um daraus beispielsweise das Produktesortiment zu optimieren oder noch gezieltere Marketingmassnahmen abzuleiten, oder aber auch heute noch unbekannte Fragestellungen aufzudecken. Unternehmungen profitieren, durch dieses zusätzliche Markt- und Kundenverständnis, welche DataScientisten mit MaschineLearning-Algorithmen und künstlicher Intelligenz aufdeckt, von Wissensvorsprung resultierend in Marktvorteilen.
BigData-Use-Cases sind in allen Branchen und entlang der gesamten Wertekette zu finden
Oracle schreibt dazu, dass BigData-Anwendungsfälle sowohl in der vorausschauenden Wartung, beispielsweise mittels IoT-Daten im Industriesektor, über Sortiments- und Preisoptimierungen im Retail-Markt, der Netzoptimierungen im Telekommunikationsbereich bis hin zur Geldwäschereibekämpfung im Finanzsektor, zu finden sind. – BigData erfüllt also viele Voraussetzungen einer möglichst genauen Datenmustererkennung , stellt Mensch und Maschine aber auch vor ganz neue Herausforderungen. So können beispielsweise bei BigData aufgrund der Velocity-Charakteristik, im Gegensatz zu strukturierten Daten, keine batchbasierten Extraktionsjobs (dazu später mehr) angewendet werden. Auch die Datenverarbeitung, beispielsweise dessen Aggregationen über solch riesigen Datenmengen, fordern höchste Flexibilität und Skalierbarkeit an die Infrastruktur und deren Kostenmodelle.
Um sowohl den klassischen BI-Anforderungen, unterschiedliche Zielgruppen datenbasiert zu unterstützen damit sie optimale Entscheidungen treffen können, als auch den Anforderungen der DataScience gerecht werden zu können, sind grundlegende Anpassungen in der Datenarchitektur unumgänglich
Während in traditionellen Data-Warehouse-Architekturen strukturierte Daten über ETL-Prozesse extrahiert, transformiert und anschliessend in Data Warehouses geladen werden, berücksichtigen Data Lake- und Data Lakehouse-Ansätze auch halb- und unstrukturierte Daten und Quellen und ermöglichen Analysen auf den Rohdaten. Die Idee hinter dem Lake-Ansatz ist also, Daten unterschiedlichster Quellen in einem „Daten-See“ zu sammeln und so, neben einer ETL-Verarbeitung, auch die Möglichkeit zu bieten, Rohdaten, beispielsweise für MachineLearning, bereitzustellen oder Rohdatenbasierte Ad-hoc-Reportings zu ermöglichen.
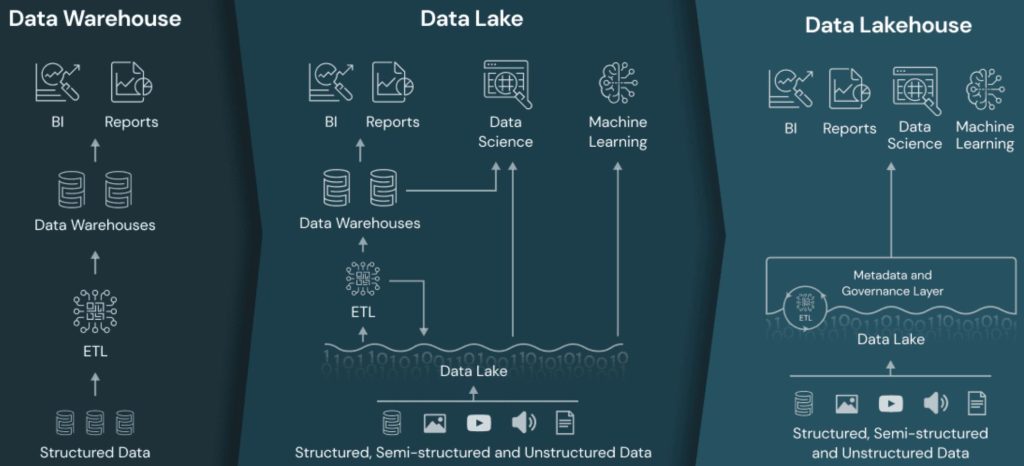
Data Warehouse vs. Data Lake, vs. Data Lakehouse (Quelle: databricks, online)
Und wie lassen sich bestehende ETL-Architekturen nun in moderne Datenplattforme integrieren?
Traditionelle Datenplattformen sind also batchbasiert, das heisst strukturierte Daten werden zu einem bestimmten Zeitpunkt, zum Beispiel jede Nacht um 02:00 Uhr, aus den relationalen Datenbanken und Quelldaten ausgelesen (Extract) und in der Staging-Area eines Data-Warehouses (DWH) auf einen physikalischen Datenträger gespeichert. In einem zweiten Schritt werden die extrahierten Rohdaten bereinigt und mit unternehmensspezifischen Informationen angereichert (Transform), bevor sie im DWH-Core abgespeichert werden. Aus dem DWH-Core werden Teildatenmengen, welche nun als «single source of truth» gelten, in Zielgruppengerechten Data-Marts geladen, von wo aus sie für Analysezwecke in BI-Plattformen, wie beispielsweise ein PowerBI-Dashboard, geladen (Load) werden.
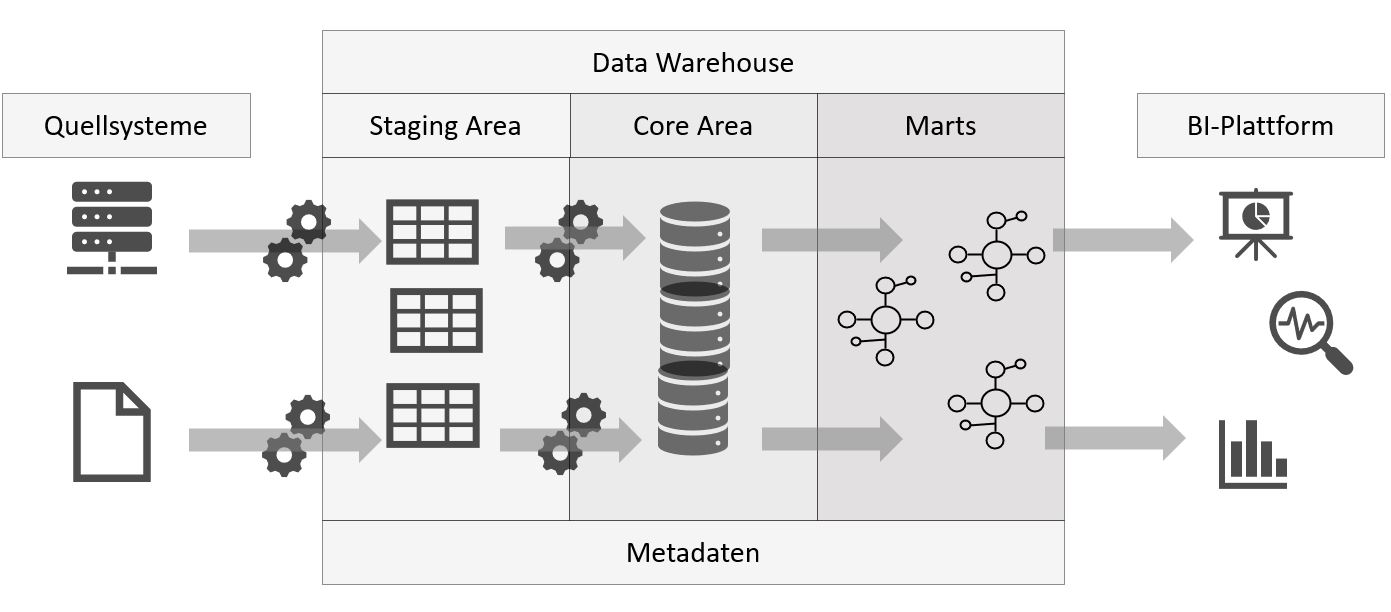
Kernelemente einer DWH-Architektur (Quelle: Philippe Christen, eigene Darstellung)
Traditionelle Datenplattforme wie jene nach Inmon oder Kimball differenzieren sich also grösstenteils von den BigData-Charakteristiken, da die Daten nicht «in-motion» sondern in Batchform verarbeitet werden, in der Regel lediglich strukturierte Datenquellen extrahiert werden und Daten ausserhalb der eigenen Organisation, beispielsweise Marktdaten, nur selten und gezielt herangezogen werden, weshalb die Wahrhaftigkeit dieser Daten in der Regel überprüfbar ist. Hinzu kommt, dass physikalische Komponenten wie CPU, RAM oder Storage in begrenzter Form zur Verfügung stehen und nur schwer skalierbar sind. Und dennoch sind traditionellen ETL-Architekturen nicht mehr wegzudenken. Es ist wahrscheinlich, dass BigData auch in Ihrem Unternehmen künftig eine zentrale Rolle spielen wird, trotzdem haben traditionelle Datenplattforme aber genauso ihre Daseinsberechtigung.
Event Processing & Data Lake-Architekturen wie jene nach Lambda oder Kappa vereinen die beiden Anforderungen eines batchbasierten DWHs und Eventbasierten-Datenströmen
So kann, wie in der folgenden Abbildung ersichtlich ist, über den «BigData Platform»-Container einen Batch-Layer für die ETL-Datenverarbeitungen angewendet werden, während im Speed-Layer über den «Stream Processing Cluster» Streams und Realtime-Auswertungen bereitgestellt werden. Über den «Event Broker», welcher als Pufferelement in der Datensammlung dient, können auch Kombination der beiden Layer realisiert werden. So ist es möglich, Daten aus «Event Sources» über den «Event Broker» beispielsweise im «BigData Platform»-Container in einer NoSQL-Datenbank abzulegen.
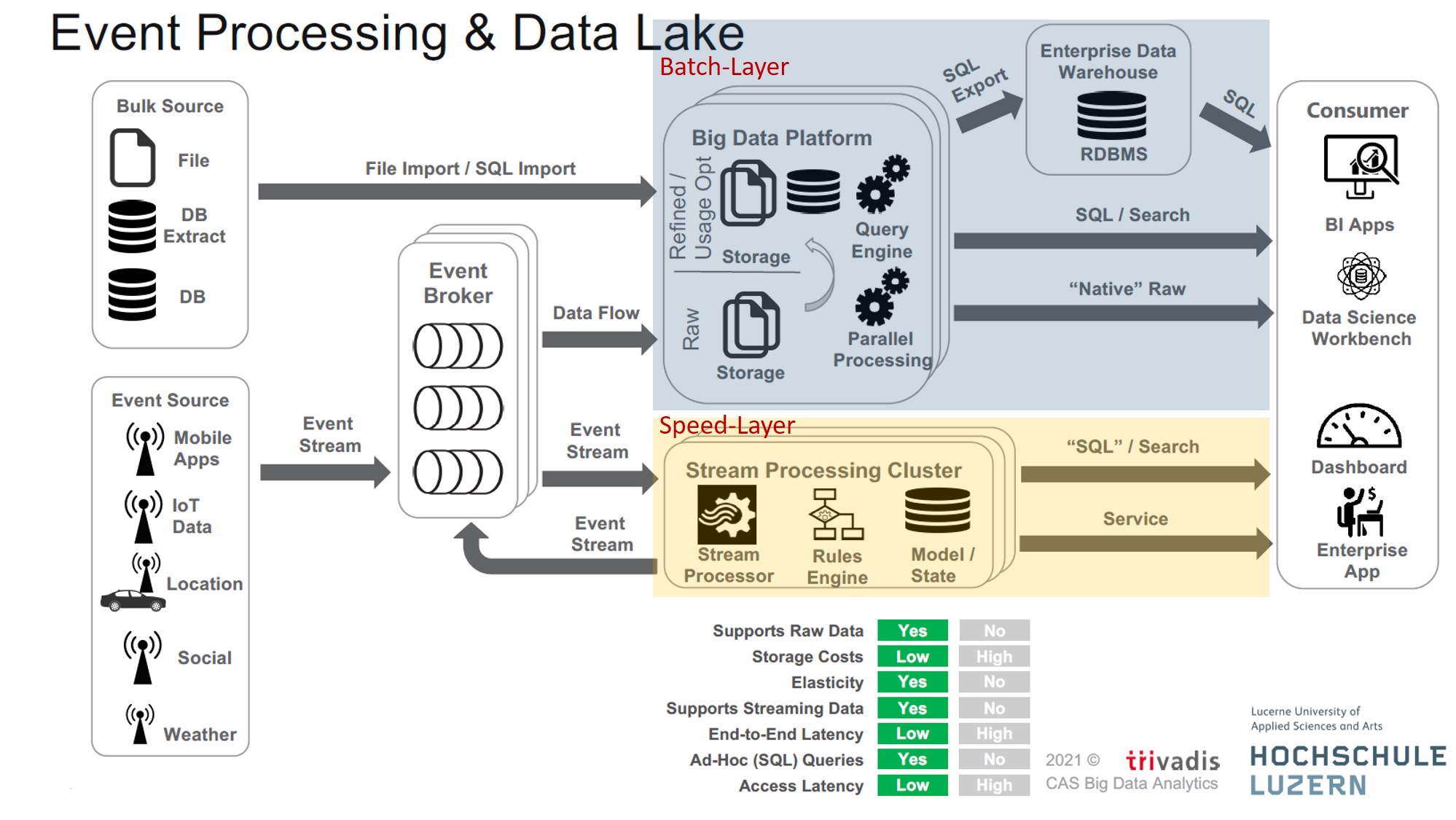
Beispiel einer Event Processing & Data Lake-Architektur (Quelle: Hochschule Luzern und trivadis)
Dank modernen Datenplattformen können im Batch-Layer die Rohdaten also auch historisiert und in der herkömmlich tiefen Granularität als Data-Warehouse in relationalen Datenbanken gehalten und weiterhin per SQL abgefragt werden, während über den Speed-Layer Realtime oder Event-basierte Streaming-Auswertungen gemacht werden können. (Teil)Daten aus eventbasierten Quellen können über den Event Broker mit strukturierten Daten kombiniert oder in NoSQL-, Graphen- oder ähnlichen Datenbanken abgelegt werden. Cloudlösungen in Kombination mit Filesystemtechnologien wie Amazon S3 oder Apache hadoop HDFS können helfen, die individuelle Skalierbarkeit von Hardware zu jedem Zeitpunkt sicherzustellen und mit moderner Speicherklassifikation Daten auch zu archivieren und so die Kosten auf ein Minimum zu reduzieren.
Die folgende Abbildung zeigt zusammengefasst einige Eigenschaften von traditionellen Architekturen und reinen Data Lake Ansätzen. Mit modernen Datenplattform wie Lamda oder Kappa lassen sich die Eigenschaften beider Ansätze vereinen:
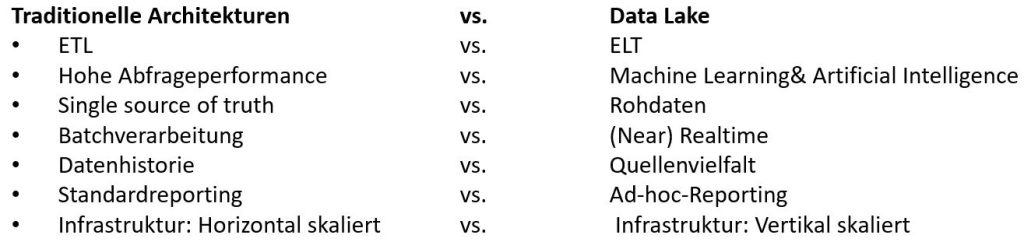
Eigenschaften von traditionellen Architekturen und reinen Data Lake Ansätzen (Quelle: Philippe Christen, eigene Darstellung)
Zusammenfassung und Ausblick
BigData, charakterisiert durch Volume, Velocity, Variety und Veracity, verspricht Chancen in zukunftsgerichteten Use-Cases aller Branchen. Der Ansatz, Rohdaten in grosser Menge unterschiedlicher Herkunft zu verwenden um Strukturen und Merkmale aus den Daten zu lesen, davon Trends abzuleiten und Marktvorteile zu erlangen ist Realität. Herausforderungen, sei es in der Datenverarbeitung, der Infrastruktur oder der Datennutzungskombination mit traditionellen Architekturen zwingen den Umstieg auf neue Ansätze wie jene von Data Lake oder dem Data Lakehouse. Dank modernen Datenplattformen wie jene nach dem Lamda- oder Kappa-Ansatz können die Vorteile von traditionellen Data-Warehouse- und Data Lake-Ansätzen genutzt und realisiert werden.
Wohin die Datenreise auch geht bzw. mit welchen Fragestellungen wir in Zukunft auch konfrontiert werden, die Entwicklung zu BigData zeigt, dass davon auszugehen ist, dass das Datenvolume, dessen Komplexität und Vielfallt weiter zunehmen werden. William Edwards, ein US-amerikanischer Physiker, Statistiker und Pionier im Bereich des Qualitätsmanagements sagte einst
„without data, you’re just another person with an opinion“.
Faktenbasierte Entscheide auf Grundlagen von Daten werden uns auch in Zukunft begleiten und womöglich den relevanten Marktvorsprung verschaffen. Aber auch traditionelle ETL-Architekturen werden uns sicherlich noch ein wenig begleiten. Für die Kombination von traditionellen ETL-Architekturen und BigData sind Investitionen in moderne Datenplattformen aber unumgänglich, nicht zuletzt auch um in Zukunft mit dem Wettbewerb Schritt halten zu können. Neben den Chancen, welche Daten ganz offensichtlich bieten, müssen auch die Herausforderungen, beispielsweise an Infrastrukturen, oder Risiken, beispielsweise von falschen Informationen in den auszuwertenden Daten, stehts vor Augen gehalten werden; auch sie werden zunehmen.