
Ich will eine einfache Frage beantworten: Wie korreliert die Anzahl Likes meiner Bilder auf Facebook mit deren algorithmisch berechneten Bildqualität? Die Antwort: Keine Ahnung! Meine Erkenntnis: Datenanalysen brauchen Zeit, Ausdauer, sind teils schwierig nachvollziehbar und machen wenig Spass, wenn man nicht an die nötigen Daten herankommt.
Als passionierter Fotograf und langjähriger Facebook User habe ich über 6’000 Bilder auf meinem Facebook Account, mal mehr mal weniger geliked von meinen ~800 Freunden. Bei meinem ersten Gehversuch in der Datenanalytik will ich herausfinden, wie die Anzahl Likes meiner Bilder mit einem algorithmisch berechneten Score der Bildqualität korrelieren. Meine Hypothese: Je höher die Bildqualität desto mehr Likes.
An die Bilder heranzukommen ist einfach
Als erstes benötige ich eine Kopie all meiner Facebook Bilder. Dies ist einfach, man kann diese jederzeit als Paket von der Plattform herunterladen. Mit etwas Aufwand und einigen Excel Tricks erstelle ich eine Tabelle mit den 6’000 Dateinamen als Basis für die statistische Kalkulation.
Die Berechnung der Bildqualität braucht Geduld
Im nächsten Schritt muss ich einen passenden Open-Source Algorithmus finden um die Bildqualität zu berechnen. Ich entscheide mich für «Image Quality», erhältlich auf Github. Dieser gibt die Bildqualität in einem Score zwischen 0 (höchste Qualität) und 100 (tiefste Qualität) an. Mittels Jupyter Notebook und einigen Tipps von meinem Studiengangsleiter kann ich durch wenige Zeilen Python Code alle Bilder automatisch prozessieren. Anhand welcher Parameter der Score berechnet wird ist nicht offensichtlich, daher die Resultate zwar interessant, jedoch wenig nachvollziehbar:
 |
 |
 |
| Score: 0 | Score: 9 | Score: 17 |
 |
 |
 |
| Score: 45 | Score: 67 | Score: 80 |
Für mich überraschend ist die Dauer von 20-40 Sekunden pro Prozessierung eines einzelnen Bildes, was bedeutet, dass mein PC drei Tage damit beschäftigt ist die 6’000 Scores zu berechnen. In der Zwischenzeit widme ich mich den Facebook Likes.
Data Ownership ist nicht immer offensichtlich
Es folgt langes Suchen in verschieden Support-Foren, ein erfolgloser Versuch mit Graph API, ein Hilferuf an einen ehemaligen Uni Kollegen, der für Facebook gearbeitet hat und schliesslich eine eher verzweifelte Anfrage an das Facebook Support Center. Das Fazit: Für Facebook gehören die Likes von meinen Bildern nicht zu meinen persönlichen Daten, sondern sind assoziiert mit dem Datensatz meiner Freunde. Facebook stellt mir nur meine persönlichen Daten zu Verfügung, was die Likes in einem verwertbaren Format ausschliesst. Aufgrund Datenschutzbedenken ist dies ist für mich grundsätzlich nachvollziehbar, bedeutet jedoch das Ende meiner ersten Datenanalyse.
Auch wenn ich meine Frage nicht beantworten konnte, habe ich viel gelernt
- Trotz Dokumentation wie der Algorithmus die Scores berechnet, ist er für Laien wie mich nicht nachvollziehbar. Ich muss auf die Verlässlichkeit des Algorithmus’ vertrauen, auch wenn Ausreisser, beispielsweise Bilder mit negativem Score, Zweifel aufkommen lassen.
- Die Datenanalyse braucht Zeit. Ich habe mich auf einen Open-Source Algorithmus beschränkt und es ist aufwändig, den passenden Algorithmus auf Github zu finden, welcher einen brauchbaren Score pro Bild produziert und mit wenig Vorwissen programmierbar ist. Die Vorbereitung des Bilder Datensets für die Auswertung im Excel erfordert Handarbeit, und wie erwähnt hat mein PC bei der Prozessierung der Scores Nachtschichten geschoben.
- Es braucht Ausdauer, gerade für Laien. Die Datenanalyse klappt selten auf Anhieb und es gibt viele Rückschläge zu bewältigen. Die Einarbeitung in Python und das Erstellen der Batch-Prozessierung hat mich ziemlich viel Schweiss gekostet, was mich zur letzten und wichtigsten Erkenntnis bringt.
- Auch wenn man sein Bestes gibt kommt man nicht ans Ziel, wenn die Daten nicht verfügbar sind. Dies kann verschiedenste Gründe haben, beispielsweise unvollständige oder nicht konsolidierte Datensets, eine fehlende Digitalisierung der Daten oder wie in meinem Fall Datenschutzrichtlinien.
Ein kleines Trostpflaster
Aus Neugierde kann ich es nicht lassen, die 6’000 Resultate der Bildqualität Scores etwas genauer anzuschauen. Und siehe da, zumindest in den Augen des Algorithmus sind meine Bilder von relativ hoher Qualität.
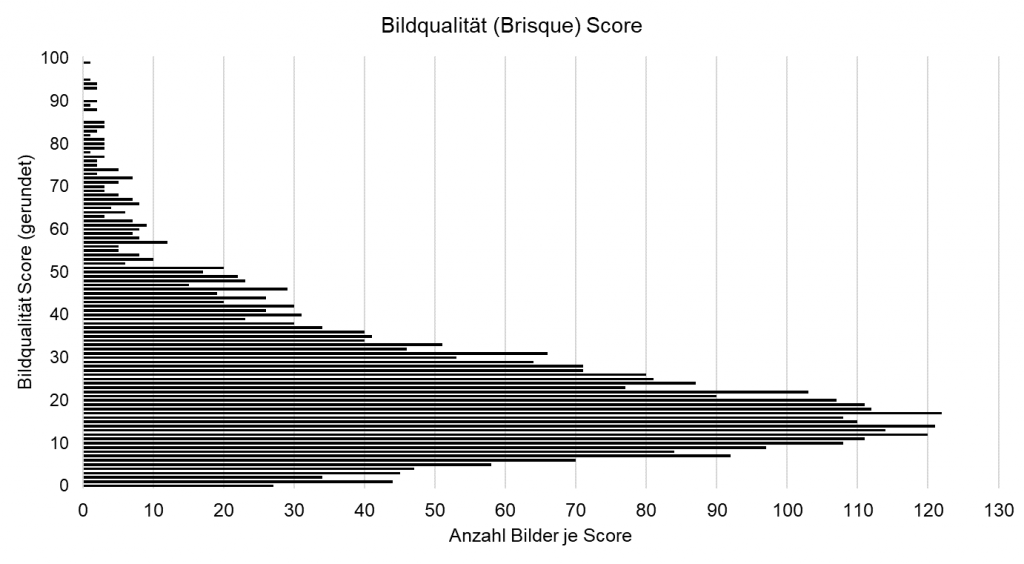
I like!
Quellenangabe: Alle Bilder & Darstellungen in diesem Blog sind © Adrian Bär