
…gibt es nicht. Aber es gibt Ansätze, mit welchen man mit einfachen Mitteln eine solide Plattform aufbauen kann.
Auf die Frage nach der perfekten BigData-Plattform erhält man oft eine ähnliche Antwort: «Es kommt darauf an…»
Jeder kocht sein eigenes Süppchen.
Viele Punkte beeinflussen die zukünftige Daten-Plattform. Unter anderem müssen folgende Fragen geklärt werden:
- Standort: On-Premise, in der Cloud, und wenn ja, in welcher Cloud?
- Skalierbarkeit: Ist die Plattform skalierbar und vermag auch steigende Anforderungen bewältigen?
- Budget: Benötige ich für mein Vorhaben teure Infrastruktur, Lizenzen und Betriebskosten?
- Datenschutz und Security: Ist das System sicher, sind es die Daten auch?
- Hochverfügbarkeit: Muss das System ausfallsicher sein, oder können Unterbrüche in Kauf genommen werden?
- Einsatzzweck: Für welchen Zweck wird das System eingesetzt?
- Art des Projektes: Realisierung eines seit Monaten geplanten Grossprojektes, eine kleine Erweiterung bestehender Infrastruktur, ein kleiner Proof-of-Concept oder ein Datenwissenschaftler welcher eine Plattform zum Üben braucht?
Anstatt einer klaren Antwort erhält man von einem Data-Engineer viele Fragen, denn was für die einen Leute die perfekte Plattform ist, kann für andere Personen ein völlig falsches Konzept sein.
Gibt es denn gewisse Grund-Zutaten, an welchen sich man orientieren kann?
Natürlich gibt es Grundsätze, welche in diesem Kontext zu einem Projekterfolg beitragen können, zum Beispiel folgendes Zitat von Steve Jobs:
Start Small, Think Big [2]
Das bedeutet in unserem Falle, die Plattform so gross zu bauen, wie nötig. Sie soll aber so konzipiert sein, dass sie aufgrund ihrer architektonischen Eigenschaften auch für zukünftige Anwendungsfälle gerüstet ist.
Als Beispiel: In einem Proof-of-Concept wird die Machbarkeit eines BigData-Projektes bewiesen. Dafür wird keine grosse Plattform benötigt, man arbeitet z.B. nur mit einem Testdatensatz. Schlecht wäre es, wenn das Projekt in die Produktions-Phase übergeht und die vorher gebaute Plattform neu konzipiert werden muss. Oder noch schlimmer, die gewählte Technologie ist in der Produktion nicht geeignet. Das Stichwort lautet Skalierbarkeit.
Wie lautet also das Geheimrezept?
Früher hat man auf den Ansatz der Vertikalen Skalierung (Scale up) gesetzt, also die Leistungssteigerung eines Einzelsystemes (z.B. ein Server) durch Hinzufügen von zusätzlichen Ressourcen. Diese Methode stösst aber irgendwann an ihre Grenzen. So ist man dazu übergegangen, horizontal zu skalieren (Scale out). Dabei werden zur Leistungssteigerung zusätzliche Systeme hinzugeschaltet, in unserem Beispiel zusätzliche Server.
Noch effizienter wird das System, wenn anstatt eines Servers Container-Applikationen horizontal skaliert werden. Der Overhead des Betriebssystemes wird auch gleich wegrationalisiert. Kein Wunder hat sich die Technologie von Containern in den letzten Jahren stark verbreitet, insbesondere im Umfeld von BigData-Landschaften.
Nebst vielen anderen Vorteilen ist es Dank der Containerisierung leicht möglich, einen Container auf verschiedensten Hosting-Plattformen zu betreiben. Kommen wir zurück zu unserem Beispiel vom Proof-of-Concept. In einer ersten Phase kann die Machbarkeit in einer Container-Umgebung, welche auf einem Notebook installiert ist, bewiesen werden. Wenn das Projekt in die Produktion übergeht, werden die Container, mit welcher die Plattform entwickelt wurde, auf einem Server-Cluster provisioniert. Oder die Container können in einer Cloud der Wahl als «Container as a Service» (CaaS) übertragen werden.
Welche Küchenhelfer eignen sich dazu?
Docker ist seit Jahren der klare Favorit, wenn es um Containervirtualisierungen geht. Viele Softwarehersteller bieten eigene Images an, mit welchen ihre Software als Docker-Container betrieben werden kann. Docker-Images können selber erstellt werden oder man kann sich ein vorgefertigtes Image vom Docker Hub herunterladen.
Gibt es denn auch ein Haar in der Suppe?
Natürlich bringt die Containerisierung auch einen «Nachteil» mit sich. Es muss zusätzliches Know-How vorhanden sein. Es reicht nicht, nur einen einzelnen Container hochzufahren. In einer modernen Anwendung oder Datenplattform werden mehrere Container eingesetzt. Diese müssen untereinander kommunizieren können, Zugriff und Sicherheit muss gewährleistet sein und die Container müssen konfiguriert werden, so dass sie skalieren können, nur um einige Beispiele zu nennen. Die Container müssen also orchestriert werden. Nicht jeder Datenwissenschaftler will sich zuerst intensiv mit dieser Technologie auseinandersetzen, nur damit er sein eigentliches Fachgebiet verwenden kann, die Datenplattform.
Im Bereich der Orchestrierung von Dockercontainern nehmen Docker-Compose und Kubernetes eine führende Rolle ein. Wobei zu sagen ist, dass der Einstieg in Kubernetes schwieriger ist, da es sehr komplex ist. Es benötigt also einigen Lernaufwand, wenn man sich als Neuling mit der Technologie auseinandersetzen will.
Was ist mit Fast Food?
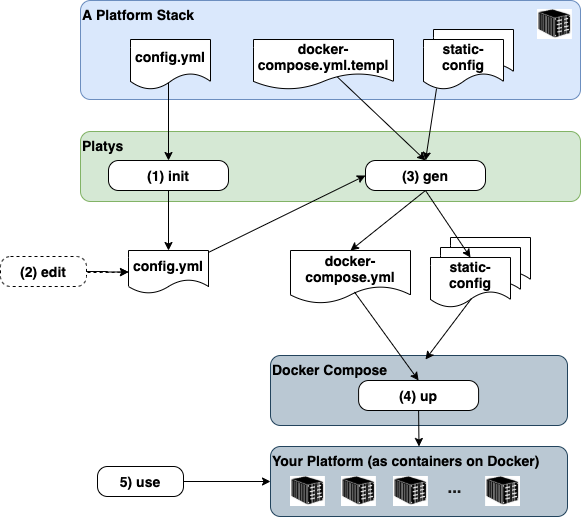
Eine schnelle Variante, eine Daten-Plattform zu provisionieren bietet das Tool Platys.
{kind=link}
Platys wird von Guido Schmutz und Ulises Fasoli von der Firma Trivadis entwickelt und gepflegt. Das Projekt ist auf Github verfügbar: https://github.com/TrivadisPF/platys
Platys ist ein Werkzeug zur Erzeugung und Bereitstellung moderner Datenplattformen auf der Basis von Docker und Docker Compose. Das heisst, es generiert aufgrund einer Vorlage automatisch die benötigten Docker-Compose-Konfigurationen. So kann die Umgebung per “Knopfdruck” angepasst werden, Dienste hinzugefügt oder entfernt werden. Der Benutzer muss sich lediglich die Dienste und Applikationen auswählen, welche er für seine Datenplattform benötigt. Der Ganze Rest wird von Platys übernommen. Eine ausführliche Anleitung, wie man eine Lokale Datenplattform mit Platys aufsetzen kann, habe ich auf meinem privaten Blog veröffentlicht: https://www.stefanko.ch/post/platys/
Was meint die Koch-Jury dazu?
Die perfekte BigData-Plattform gibt es nicht, aber es gibt gute Ansätze, nach welchen man sich richten kann. Wenn man seine Plattform auf Containerisierung ausrichtet, wählt man eine Technologie, welche zukunftssicher ist. Der Einsatz von Platys erleichtert den Einstieg in den Umgang mit Docker. Wenn der Einsatz in Richtung Produktion geht, sollte die Implementation der Orchestrierung aber von einem Fachspezialisten übernommen werden. Hat man seine BigData-Plattform mit Platys getestet, kann der Profi sie dann ohne viel Aufwand überführen.
In den letzten Wochen habe ich mich ausführlich im Rahmen meiner Transferarbeit mit Docker und Platys auseinandergesetzt. Ich bin begeistert und kann es nur weiterempfehlen. ☺️
Quellen
[1] Titelbild: https://unsplash.com/photos/mDOGXiuVb4M