
Die rasante Entwicklung generativer KI und der Erfolg von ChatGPT haben unsere Interaktionen mit Technologie revolutioniert. Doch lohnt sich der Blick über den beliebtesten Chatbot hinaus? Definitiv! Mit Prompt Engineering und dem richtigen Werkzeug ist der Vergleich nicht nur sinnvoll, sondern macht auch noch Spass.
Spätestens seit dem Launch von ChatGPT Ende 2022 sind Large Language Models (LLMs) kaum mehr aus unserem Alltag wegzudenken. Dass sich generative KI-Modelle grosser Beliebtheit erfreuen, zeigt sich nicht nur in den millionenschweren Investments von OpenAI, Google und Microsoft. Mit der wachsenden Nutzung verändern sich auch die Anwendungsbereiche, wie der Artikel How People Are Really Using Gen AI in 2025 feststellt: Sie entfernen sich von technischen Anwendungen und werden zunehmend persönlicher und emotionaler.
Viele von uns verwenden Chatbots im Alltag und bei den meisten dürfte es sich um ChatGPT von Open AI handeln. Darauf lassen die Marktanalysen der KI-Suchanfragen schliessen: Mit einem Marktanteil von 60,6 % führt ChatGPT den Bereich der KI-Suchanfragen klar an, weit vor dem zweitplatzierten Copilot von Microsoft mit 14,3 %.
Angesichts dieser Dominanz stellt sich die Frage: Lohnt sich der Blick über ChatGPT hinaus überhaupt? Und falls ja, wie vergleicht man die Modelle, um seine eigenen Ergebnisse gezielt zu optimieren?
Ein Blick über den KI-Tellerrand
Verschiedene KI-Modelle haben unterschiedliche Stärken und manchmal auch Schwächen. Die Zeit, um das passende Modell zu finden, ist aus verschiedenen Gründen gut investiert:
- Spezialisierung der Modelle
KI-Modelle eignen sich, abhängig von ihrem Training, für spezifische Aufgaben. Beispielsweise glänzt Google Gemini 2.5 beim Multitasking und Analyse grosser Dokumente, während Anthropic’s Claude 3 beim differenzierten Schlussfolgern punktet. - Kompetenz durch Vergleich
Wer verschiedene Modelle ausprobiert, erhält einen Überblick der Fähigkeiten und Limitierungen (z. Bsp. «halluzinieren» bzw. das Erfinden von Fakten) von generativer KI. Zudem wird die eigene Kompetenz im Umgang mit der Technologie gestärkt. - Kosten vs. Nutzen
Wer sich für eine kostenpflichtige Premiumversion mit zusätzlichen Funktionen und höherer Rechenleistung entscheidet, sollte nicht nur auf den Preis achten. Ein gut gewähltes Modell kann die Arbeit erleichtern, während ein unpassendes schnell zur Fehlinvestition wird.
Aber wie lassen sich die Modelle vergleichen? Eine Möglichkeit bietet das Open-Source-Werkzeug AI SDK Playground von Vercel. Über die Benutzeroberfläche können Modelle getestet und die Unterschiede verglichen werden.
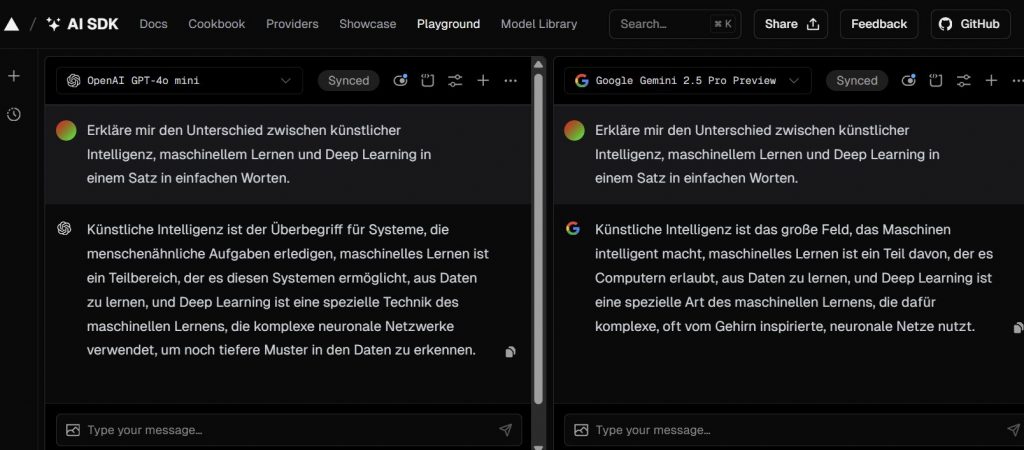 Interface des AI SDK Playgrounds mit einem Beispiel-Prompt (Bildquelle: Jasmin Rütsche)
Interface des AI SDK Playgrounds mit einem Beispiel-Prompt (Bildquelle: Jasmin Rütsche)
Wie ein gutes Gespräch – mit Prompt Engineering zum Ziel
Zum richtigen Werkzeug gehört auch die passende Anwendung. Wer die Qualität der Antworten erhöhen will, kann Prompt Engineering anwenden: Mit verschiedenen Strategien und Techniken wird das KI-Modell gezielt gesteuert. Gut formulierte Prompts führen neben besseren Ergebnissen nicht nur schneller zur Lösung, sondern ermöglichen auch die Kontrolle über Ton, Länge und Format. Der Begriff «Engineering» mag technisch klingen, aber wirksames prompten gelingt auch ohne Programmierkenntnisse.
Eine bewährte Methode ist das RISEN-Framework, welches Prompts wie folgt strukturiert:
- Role: Definition einer Rolle oder Persona, um den Kontext zu setzen.
- Instructions: Formulierung der zentralen Aufgabe in präzisen Anweisungen.
- Steps: Aufteilung der Aufgabe in einzelne, aufeinanderfolgende Schritte für eine klare Umsetzung.
- End Goal: Definition von spezifischen Zielen, um das gewünschte Resultat zu erhalten.
- Narrowing: Einschränkung des Antwortspielraum mit Vorgabe von Abhängigkeiten oder Schlüsselanforderungen.
Drei KIs, ein Prompt – ein Selbstversuch
Auch ich nutze hauptsächlich ChatGPT, also höchste Zeit für einen Selbstversuch. Ich habe einen Prompt für die Erstellung eines Schulungskonzepts drei KI-Modellen übergeben. Das Resultat zeigt: Die Wahl des passenden KI-Modells beeinflusst Stil und Nutzwert der generierten Inhalte. Während Perplexity Sonar eine kompakte, aber eher oberflächliche Antwort liefert, punktet GPT-4o mini mit klarer Struktur. Mein Favorit ist jedoch Gemini 2.5 preview, das neben einem zielgerichteten, gut strukturierten Inhalt auch konkrete Vorschläge für die Vorbereitung der Schulung bietet.
Mein Fazit: Künftig werde ich je nach Anwendungsfall verschiedene Modelle testen, statt automatisch zur gewohnten Lösung zu greifen.
Weiterführende Links zum Thema:
- Leitfaden zum Prompt-Engineering: Prompt Engineering Guide
- Bestenliste der LLM je Task: LMArena Leaderboard
- Blogbeitrag zur Wahl des richtigen LLM: TeamAI Guide Choosing the right LLM
- Überzeugend formuliert, aber inhaltlich falsch: What are LLM Hallucination?
- Zum Ausprobieren als PDF: Prompt-Schulung-RISEN-Framework