
Die drei Buzzwords Data Warehouse, Data Lake und Data Mesh sind allgegenwärtig vertreten auf den Technologie-Trend Slides der Consulting Firmen – grundlegend neu sind die Begriffe aber nicht. Die Schlagwörter unterscheiden sich durch feine Nuancen hinsichtlich Aufgabengebiet, Organisation, Datentypen oder Benutzer. Es stehen jedoch alle Begriffe im Dienste der Datenspeicherung von Small und Big Data.
Einsatzgebiete
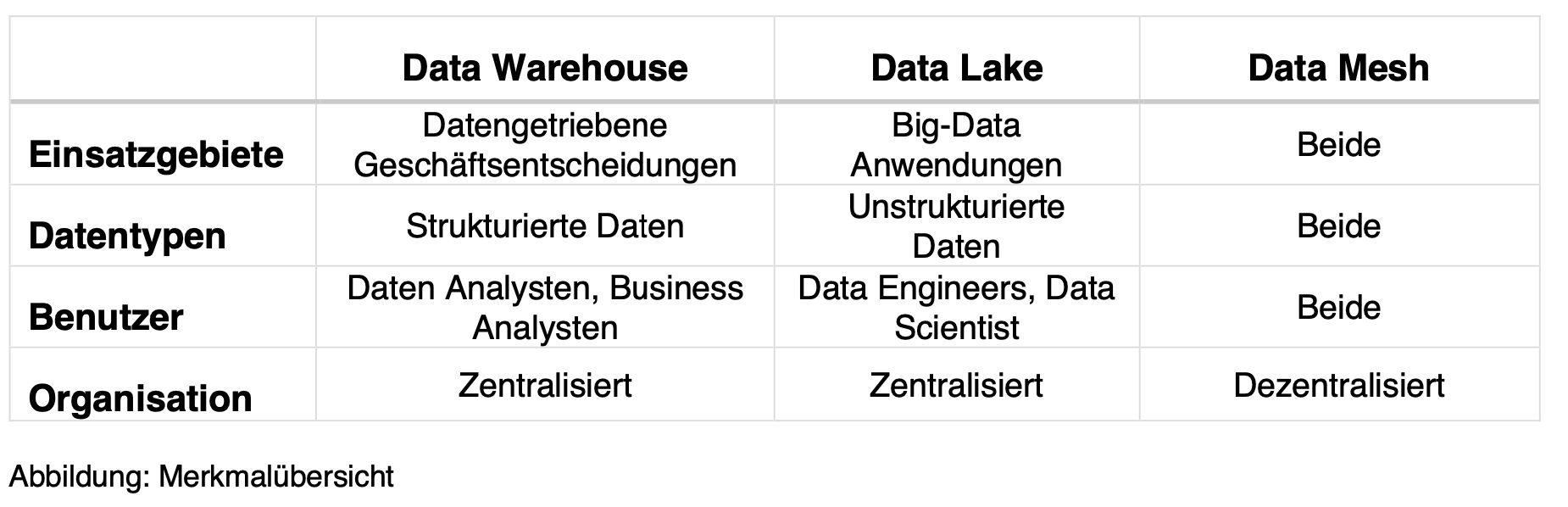
Das Datawarehouse legt die Basis für datengetriebene Geschäftsentscheidungen. Dabei zentralisiert und konsolidiert das Data Warehouse im ETL-Prozess grosse Datenmengen aus unterschiedlichen Quellen. Die Abfragen aus dem Data Warehouse sind typischerweise schreibgeschützt und fliessen automatisch oder manuell in die Dashboards der Anwendungsbereiche. Empfänger der Daten sind beispielsweise Sales-, Lagerbestands- und Budget-Dashboards die auf Qlik oder Power BI visualisiert sind.
Der Data Lake fokussiert sich tendenziell auf Big-Data Analysen wie Deep Learning, Predictive-Analytics oder Cyber Security. Im Data Lake werden die Daten bewusst nicht aufgearbeitet, sondern in Rohform abgelegt. Die Einsatzgebiete würden sich bei aufgearbeiteten Daten zunehmend einschränken.
Datentypen
Im Data Lake taumeln sich strukturierte als auch unstrukturierte Daten von internen als auch externen Quellen. Die eindeutige Verwendung der Daten ist meist ungewiss. Fotos, PDF Files oder Tweets sind Beispiele für unstrukturierte Datentypen, die noch kein Cleaning durchlaufen haben.
Da geht es im Datawarehouse etwas strukturierter einher. Im DWH werden historische Daten so aufgearbeitet, dass sie in ein relationales Datenbankschema passen. Das Data Warehouse speichert zudem nur Daten ab, die eine Verwendung im Unternehmen finden. Zu diesen Beispielen zählen Transaktionsdaten oder Kennzahlen. In der Praxis gibt es aber auch Mischformen von DWH und Data Lakes.
Speichergrösse
Im Data Warehouse werden nur analyserelevante Daten gespeichert – je nach Grösse des Unternehmens kommen einige Firmen mit ein paar Terrabytes oder Gigabytes bereits klar. Dieser Datenspeicher wäre womöglich beim Data Lake innert kürze ausgereizt. Data Lakes können je nach Anwendung schon einmal in Richtung Pettabytes gehen.
Benutzer
Im Data Lake taumeln sich Data Scientists und Data Engineers. Die Data Engineers schliessen Pipeline um Pipeline an und versuchen den See mit zusätzlichen Daten zu fluten. Die Scientists sind ihrerseits bemüht, aus den unstrukturierten Daten gewisse Muster abzuleiten und daraus Insights zu generieren. Im Data Warehouse findet sich dann die etwas weniger datenaffine Gruppe zurecht: Die Daten Analysten und Business Analysten. Sie ziehen strukturierte Datensätze, um Fragestellungen aus dem Business beantworten zu können.
Organisation
Hinsichtlich der Organisation sind Data Warehouse als auch Data Lake personell und technisch zentral organisiert. Die personellen Ressourcen für Unterhalt und Operations sind in einem Team zusammengefasst und die Daten liegen zentral auf einem Server. Dieser zentrale Ansatz bringt aber ab einer bestimmten Unternehmensgrösse Nachteile mit sich: Die Daten Teams sind zu weit entfernt von den Konsumenten und können den Bedürfnissen nicht gerecht werden. Um diese Herausforderung zu meistern, suchen mehr und mehr Unternehmen im Data Mesh die Lösung. Im Gegensatz zu den beiden klassischen Modellen organisiert sich ist der Data Mesh personell aber auch mit der Infrastruktur dezentral. Dieses organisatorische Umdenken soll Geschwindigkeit und Innovationskraft fördern. Der Data Mesh unterscheidet sich in den Bereichen Speichergrössen, Benutzer, Datentypen nicht massgebend von den anderen beiden Modellen. Data Mesh ist vor allem ein organisatorischer Ansatz.
Ausblick
Obwohl das Data Warehouse, der Data Lake und der Data Mesh unterschiedliche Ansätze verfolgen, können die drei Strategien als komplementär für die Datenspeicherung angesehen werden. Speziell als datengetriebenes Unternehmen wäre es falsch, nur einen Ansatz zu verfolgen. Der Data Mesh unterscheidet sich hauptsächlich durch die dezentrale Komponente und ist damit absolut zukunftsfähig: Daten müssen möglichst nahe an den Endkonsumenten aufgearbeitet und zur Verfügung gestellt werden. Beim Data Mesh werden die Daten als Produkt behandelt und mit Domain Wissen angereichert . Um das Ziel eines verteilten Datennetzes zu erreichen, gilt in vielen Unternehmen aber zuerst die Etablierung eines neuen Kredos: Das Kredo des freien Datenflusses.
Weiterführende Links zum Thema