Ich nutze das Portal meiner Sportuhr und ein Expertentool zur Trainingsauswertung täglich. Trotzdem stellte ich mir irgendwann eine grundlegende Frage: Was steckt hinter diesen Dashboards, und was zeigen sie mir nicht? Im CAS Business Intelligence & Analytics an der HSLU wollte ich genau das herausfinden – und dabei erlernte Tools an einem echten Praxisbeispiel erproben und mein Wissen vertiefen. Die Erkenntnisse haben meine Erwartungen deutlich übertroffen.
Vom bekannten Tool zur unbekannten Tiefe
Meine Expertentools zur Trainingsauswertung zeigen mir vieles: Trainingslast, Schlafqualität, Herzfrequenz, Erholungsstatus. Ich vertraue diesen Werten, hinterfragt habe ich sie jedoch nie. Was berechnen diese Tools eigentlich genau? Und gibt es Muster in meinen Daten, die kein fertiges Produkt je gefunden hat, weil ich aber auch nie danach gefragt habe?
Der Datenexport meiner Sportuhr liefert eine ZIP-Datei mit über 8000 JSON-Dateien. JSON stellt einzelne Einträge durchaus lesbar dar – aber die Gesamtstruktur von tausenden Dateien ohne Inhaltsverzeichnis zu verstehen, ist ohne Code kaum möglich. Mit einem Python-Skript, das ich innert kurzer Zeit mit einem KI-Assistenten entwickelt habe, bekam ich eine vollständige Übersicht: 19 Datenkategorien, von täglicher Aktivität über sekundengenaue Herzfrequenz bis zu rohen Messwerten. Sichtbar wurden auch die Millisekunden zwischen jedem Herzschlag – der Rohstoff, aus dem meine Uhr ihren Erholungsscore berechnet.
Meine eigenen Hypothesen auf dem Prüfstand
Wer täglich eine Sportuhr trägt, entwickelt Theorien. Meine lauteten: Wenn ich viel trainiere, sinkt mein Ruhepuls – und nach guten Nächten ist meine Erholung messbar besser. Beide Annahmen klingen plausibel. Beide waren statistisch nicht nachweisbar.
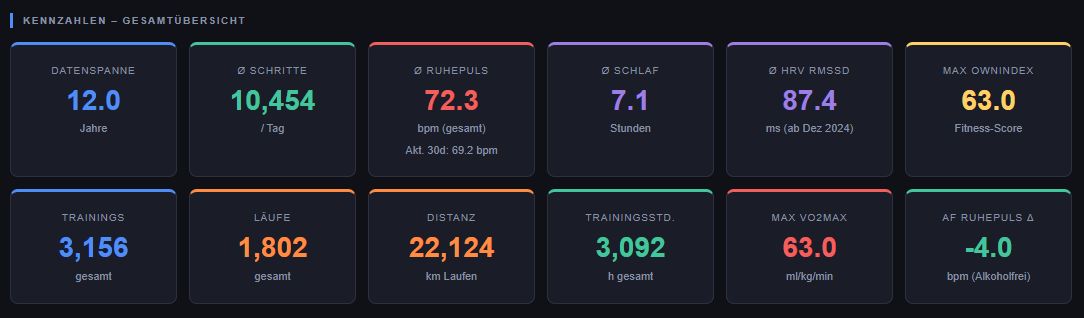
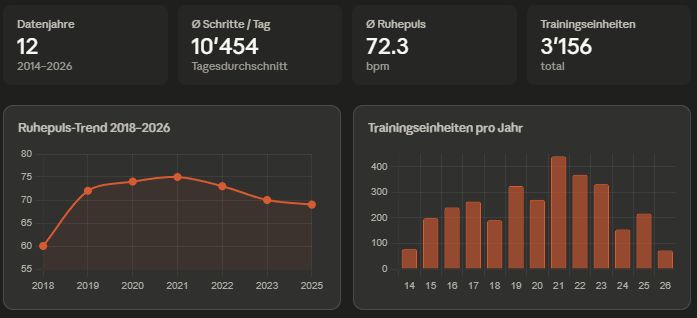
Die Korrelationsanalyse über 12 Jahre umfasste 2714 Tage, 929 Trainingseinheiten und über 1700 Tage mit Herzfrequenzmessungen. Das Ergebnis war eindeutig: kein Zusammenhang zwischen Trainingsvolumen und Ruhepuls (r = -0.04), keiner zwischen Schlafdauer und Ruhepuls am Folgetag (r = 0.02). Das ist kein Fehler in den Daten, sondern ein Ergebnis. Die eigene sportliche Intuition und die statistische Realität über 12 Jahre können zwei sehr unterschiedliche Dinge sein.
Das Muster, das ich nicht gesucht hatte
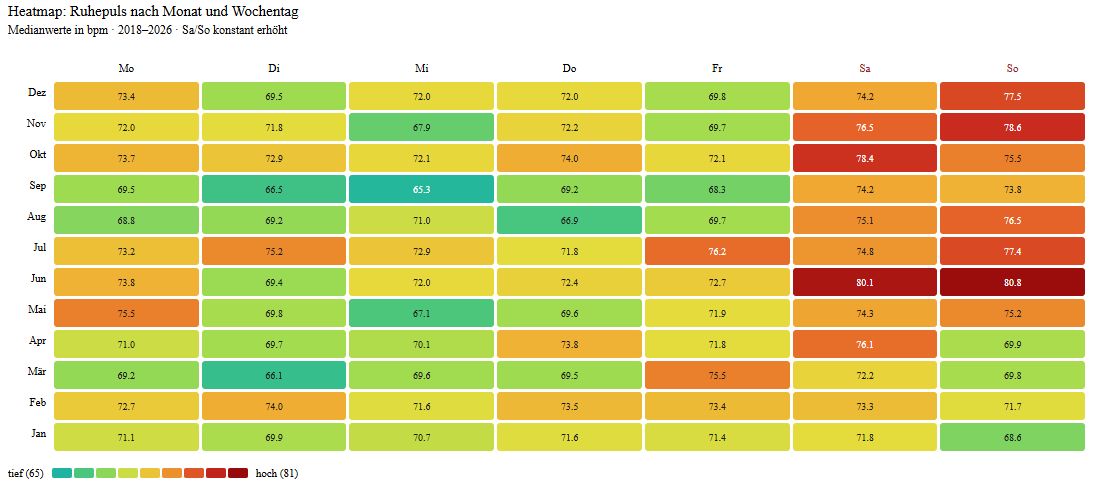
Stattdessen lieferten die Daten eine Heatmap, die ich nie geplant hatte. Eine Gegenüberstellung von Ruhepuls nach Monat und Wochentag enthüllte ein klares, stabiles Muster: Mein Ruhepuls ist an Wochenenden systematisch 6 bis 8 bpm höher als unter der Woche, in jedem Monat, über alle Jahre. Das Expertentool zur Trainingsauswertung hatte mir das nie angezeigt.
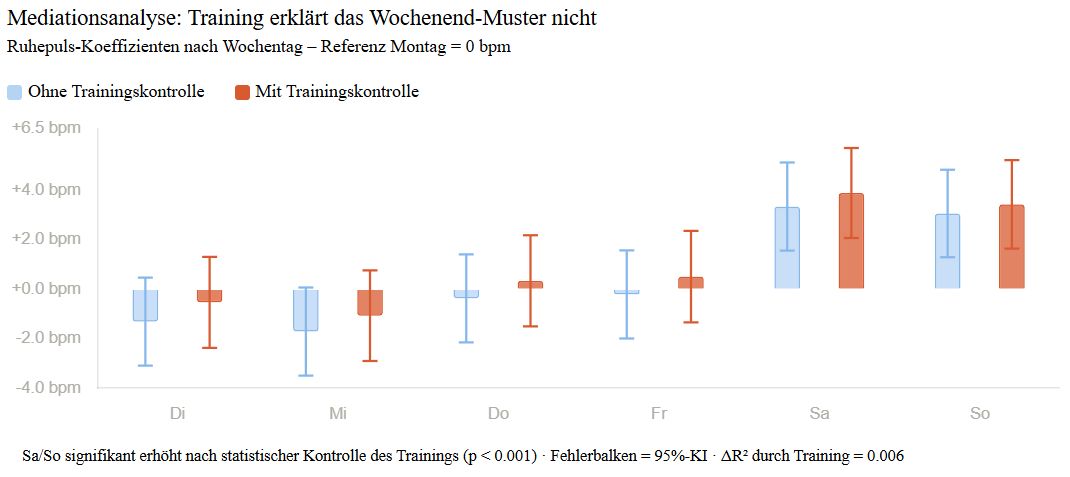
Die naheliegende Erklärung war schnell formuliert: Ich trainiere am Wochenende länger und intensiver. Eine Mediationsanalyse widerlegte das jedoch. Selbst nach statistischer Kontrolle des Trainings bleibt der erhöhte Wochenend-Puls bestehen und wird sogar etwas grösser. Dafür lieferte eine weitere Analyse einen echten Hinweis: nicht die Schlafdauer, sondern die Schlafqualität zeigt einen messbaren Zusammenhang mit dem Ruhepuls (r = -0.109). Schlechtere Schlafqualität geht mit höherem Ruhepuls einher.
Das Wochenmuster ist damit noch nicht vollständig erklärt. Auch das ist Business Intelligence: nicht nur Muster finden, sondern ehrlich benennen, wo Antworten aufhören.
Der Weg ist lehrreicher als das Ziel
Das interaktive Dashboard mit sechs Charts und persönlichen Kennzahlen ist das sichtbare Ergebnis. Der eigentliche Wert lag im Prozess, und dieser verlief nicht linear.
Die erste technische Lösung funktionierte: ZIP-Export einlesen, Deltas erkennen, Daten in eine Cloud-Datenbank schreiben. Sie scheiterte daran, dass der Hersteller nur monatlich Datendownloads erlaubt. Die Lösung lag in der offiziellen Hersteller-API, über die sich Trainingsdaten direkt und fortlaufend abfragen lassen. Vollständig ist sie noch nicht, aber sie ist nachhaltig.
Was kostenfreie Tools und Vibe Coding leisten können
Was mich beeindruckt: Der gesamte Stack basiert auf kostenfreien Tools. GitHub Codespace, Python, Databricks Free Edition, Claude.ai – alles zusammen ergab eine Analyseumgebung, die vor wenigen Jahren professionellen Teams vorbehalten war.
Den grössten Schub bei der Umsetzung brachte Vibe Coding. Die eigentliche Herausforderung für mich war es, den erzeugten Code zu verstehen, die Resultate kritisch zu prüfen und statistische Ergebnisse korrekt zu interpretieren. Eine Korrelation ist kein Beweis, statistische Signifikanz nicht automatisch Relevanz. Genau hier braucht es Grundverständnis – und den Mut, auch unbequeme Antworten stehen zu lassen.
Dieser Text wurde mit KI-Unterstützung optimiert.