
Viele Betriebe haben bereits ein Data Warehouse oder DataLake – für ERP, CRM und Verkaufsdaten. Was fehlt: die Maschinen selbst sprechen nicht damit. SPS-Systeme und Historian-Server zeichnen sekündlich wertvolle Daten auf – Temperaturen, Fehlercodes, Laufzeiten. In vielen Betrieben werden sie nicht systematisch integriert. Dabei liegt genau dort der grösste Hebel: Erst wenn Maschinendaten und Geschäftsdaten zusammenkommen, wird aus einer Störung eine Prognose, aus einem Fehlercode ein Frühwarnsignal – und aus reaktiver Instandhaltung ein echtes Frühwarnsystem.
Das fehlende Puzzlestück
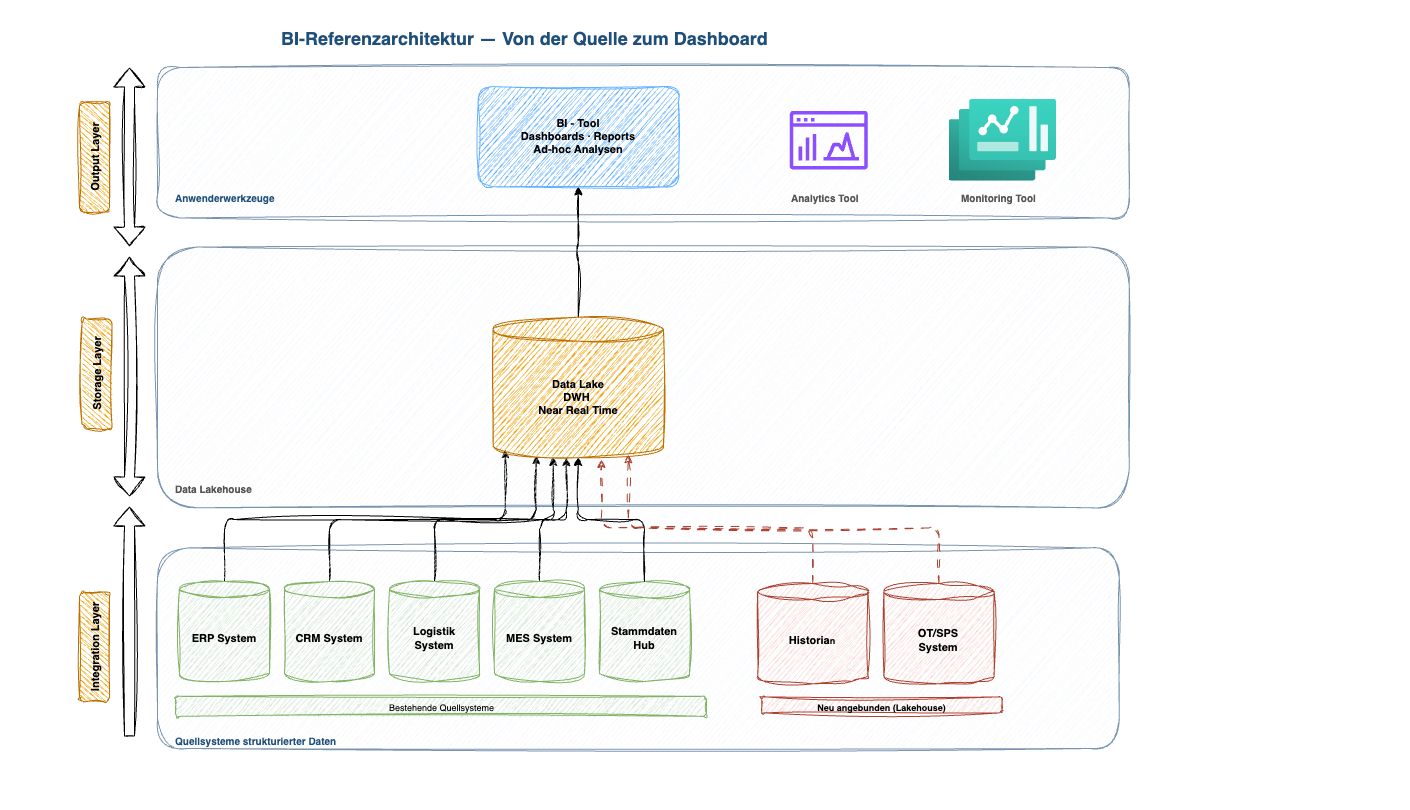
Wer einen typischen Produktionsbetrieb anschaut, sieht folgendes Bild: ERP-System, CRM, MES – all diese Daten fliessen ins Data Warehouse, oder DataLake. Und dann gibt es die Produktionsanlagen. Jede SPS (Speicherprogrammierbare Steuerung) und jeder Historian-Server – das sind die Datenrekorder der Maschinen – zeichnet sekündlich auf: Temperaturen, Fehlercodes, Laufzeiten. Diese Daten existieren. Sie werden nur nicht genutzt. Sie liegen auf lokalen Servern in der Produktion, isoliert vom Rest der Datenlandschaft.
Das eigentliche Problem
Nicht fehlende Daten sind das Problem – sondern fehlende Verbindung.
Eine Anlage, die dreimal pro Woche einen Fehlercode wirft, ist für sich allein eine Warnung.
Erst wenn man weiss, dass diese Anlage nächste Woche 80 % der dringenden Kundenaufträge
produzieren soll, wird aus einer Warnung ein kritisches Risiko.
Die Lösung: bestehend erweitern, nicht ersetzen
Das bestehende Data Warehouse bleibt. Was hinzukommt, ist ein erweiterter Datenpfad – ein Data Lakehouse. Eine solche Plattform ist flexibel genug für Maschinenzeitreihen und gleichzeitig strukturiert genug für klassisches Reporting. Die Daten durchlaufen drei Stufen:
| Stufe | Inhalt | Beispiel aus der Produktion |
| Bronze (Raw) |
Rohdaten, unverändert | SPS-Fehlercodes, ERP-Aufträge – genau so wie sie ankommen |
| Silver (Curated) |
Bereinigt, verknüpft | Störungshistorie + Produktionslast + Liefertermine in einem Datensatz |
| Gold (Serving) |
BI-fertig, auswertbar | Risiko-Score pro Anlage, Frühwarnsignal für die Instandhaltung |
Medallion-Architektur – Rohdaten werden schrittweise zu auswertbaren Informationen veredelt
Drei Signale – ein Handlungssignal
Vorausschauende Instandhaltung (Predictive Maintenance) klingt nach KI. In der Praxis beginnt es viel einfacher. Ein vereinfachtes Beispiel zeigt, wie das aussehen könnte – man stellt drei bereits vorhandene Informationen nebeneinander:
| Signal | Woher | Was es bedeutet |
| Störungsfrequenz | OT-Historian: 3x Fehlercode in 7 Tagen | Komponente zeigt Verschleiss |
| Produktionslast | ERP: nächste Woche 45% mehr Aufträge | Anlage wird stark beansprucht |
| Liefertermin-Druck | CRM: 3 Prio-A Aufträge, Lieferung in 4 Tagen | Stillstand wäre existenzbedrohend |
| → Ergebnis | Risiko: HOCH | Wartung sofort einplanen |
Drei Signale aus drei Systemen – erst zusammen ergibt sich ein Handlungssignal
Kein Machine Learning nötig im ersten Schritt. Ein einfacher Schwellenwert reicht – und spart im Ernstfall Kosten, Stillstandsstunden und unnötigen Ärger.
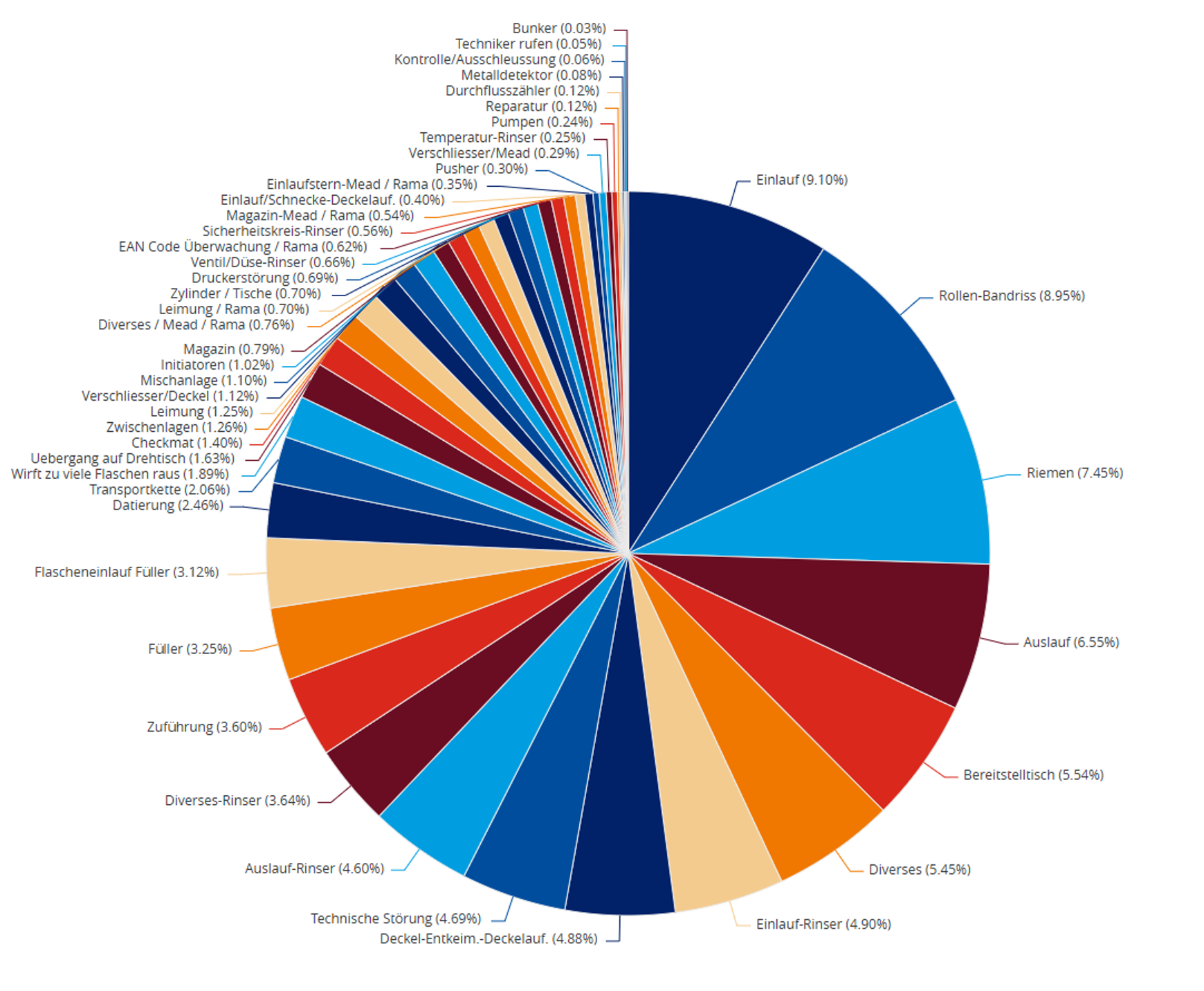
So sehen verbundene OT- und ERP-Daten in der Praxis aus – Störungen werden sichtbar, bevor sie eskalieren:
Wo anfangen – ein pragmatischer Einstieg in vier Schritten
- OT-Daten sichten: Welche Historian-Server oder SPS-Systeme zeichnen bereits auf? Die Daten sind meist vorhanden – nur nicht zugänglich.
Sicherheit zuerst: Vor jeder Anbindung müssen Netzwerksegmentierung und kontrollierte Zugänge sichergestellt sein. OT-Daten dürfen nicht ungesichert ans Data Lakehouse angebunden werden – Purdue-Modell und PAM (Privileged Access Management) sind Voraussetzung. Mehr dazu in meinem OT-Security-Beitrag (CAS IT Management & Agile Transformation).
- Eine Anlage wählen: Eine kritische Maschine als Pilotprojekt – nicht alle gleichzeitig.
- Ersten Join machen: Störungshistorie + ERP-Produktionslast verbinden. Dieser Schritt allein liefert bereits ein Frühwarnsignal – ohne CRM, ohne ML.
- Visualisieren: Eine einfache Risiko-Ampel pro Anlage genügt. Die Instandhaltung braucht Klarheit, nicht Komplexität.
Kein Big-Bang nötig
Das bestehende Data Warehouse bleibt unangetastet. Der Historian-Server wird parallel angebunden.
Phase 1 (ERP + OT) liefert bereits Mehrwert. CRM und Logistik folgen in Phase 2.
Reale Hürden nicht unterschätzen: Unterschiedliche Zeitstempel, inkonsistente Anlagencodes und ungeklärte Verantwortlichkeiten zwischen Produktion, IT und Daten-Team sind die häufigsten Stolpersteine. Wer sie früh kennt, kommt schneller zum ersten Ergebnis.
Fazit: BI als Frühwarnsystem
Business Intelligence endet nicht beim monatlichen Report. In der Produktion kann BI zum operativen Frühwarnsystem werden. Die Voraussetzungen sind in den meisten Betrieben bereits vorhanden – ERP, OT-Daten, CRM. Was fehlt, ist die Verbindung.
Eine moderne Datenplattform – häufig als Data Lakehouse – kann diese Integration ermöglichen. Entscheidend ist nicht die Architekturbezeichnung, sondern die konsequente Zusammenführung von Business- und Maschinendaten.
Für produzierende Unternehmen bedeutet das: weniger Stillstände, höhere Lieferfähigkeit und direkte Auswirkungen auf Umsatz und Kundenzufriedenheit.
Predictive Maintenance beginnt nicht mit KI – sondern mit Kontext.