
Kann ein Machine Learning Modell wirklich vorhersagen, ob Real Madrid gegen Atlético gewinnt oder PSG gegen Liverpool unentschieden spielt? In diesem Beitrag zeige ich euch, wie ich ein Multiclass Machine Learning Modell gebaut habe, welches genau das für die UEFA Champions League 2025 versucht – inklusive der Tools, Tricks und Learnings auf dem Weg dorthin.
Die Champions League ist nicht nur das prestigeträchtigste Turnier im Vereinsfussball, sie ist auch ein Paradies für Zahlenfans, Statistiker – und mittlerweile auch für Machine Learning Modelle. In meinem jüngsten Projekt habe ich genau das versucht: ein ML-Modell zu bauen, das auf Basis historischer Spieldaten vorhersagt, ob ein Spiel mit Heimsieg, Unentschieden oder Auswärtssieg endet. Klingt cool? Ist es auch – aber der Weg dahin war etwas holpriger als gedacht.
Von Datenchaos zu Datenbasis
Gestartet bin ich mit einem riesigen Dataset von über 228’000 Spielen aus verschiedenen europäischen Ligen seit dem Jahr 2000. Das Dataset sah zunächst vielversprechend aus, war aber auch ordentlich zugemüllt: über 2,4 Millionen fehlende Werte, wild verstreute Ligen und unzählige irrelevante Spalten. Nach einem sauberen Data Cleaning blieben rund 20.000 Datensätze übrig – fokussiert auf die letzten 5 Jahre und nur mit den Teams, die 2025 auch wirklich in der CL spielen.
Das Dataset findet ihr übrigens auf Kaggle:
https://www.kaggle.com/api/v1/datasets/download/adamgbor/club-football-match-data-2000-2025)
Features, Features, Features
Aus rohen Matchdaten allein lässt sich noch kein Treffer erzielen. Deshalb kamen jede Menge selbst erstellte (historische) Features dazu: Teamform über die letzten Spiele, Tore in Halbzeit vs. Spielende, Eckstösse, Schüsse aufs Tor – sogar die Performance in direkten Duellen.
Und welches Modell bringt’s?
Ich habe drei ML-Modelle ins Rennen geschickt: Logistic Regression, Decision Tree und Random Forest. Nach klassischer Trainings- und Validierungsaufteilung (70/30) wurde fleissig an den Hyperparametern geschraubt, um das Beste aus den Algorithmen rauszuholen.
Kleine Herausforderung: Die Zielvariable (Match-Ergebnis) ist ungleich verteilt – Heimsiege kommen häufiger vor als Auswärtssiege oder Unentschieden. Das wurde mit SMOTE-Oversampling ausgeglichen, damit das Modell nicht nur die Favoriten bevorzugt.
Weitere Links zu Supervised Learning und zu den Algorithmen:
Achtelfinaltipps vom Modell
Zum Schluss habe ich das Modell auf die echten CL-Achtelfinalbegegnungen vom 04. März 2025 losgelassen. Die Predictions:
- Real Madrid vs. Atlético Madrid: Unentschieden
- PSG vs. Liverpool: Unentschieden
- Benfica vs. Barcelona: Heimsieg
- Club Brugge vs. Aston Villa: Auswärtssieg
- PSV Eindhoven vs. Arsenal: Auswärtssieg
- Feyenoord vs. Inter Milan: Auswärtssieg
- Dortmund vs. OSC Lille: Auswärtssieg
- FC Bayern München vs. Leverkusen: Auswärtssieg
Ob das Modell damit richtig lag? Naja, nicht ganz: 3 von 8 Spielen hat mein Modell das Ergebnis richtig vorhergesagt – beim Rest? Pustekuchen.
Die Ergebnisse
Logistic Regression war insgesamt am stabilsten, besonders bei Heimsieg- und Auswärtssieg-Prognosen (ROC-AUC > 0.7), aber Unentschieden blieben das Sorgenkind (Accuracy nur bei ca. 23%).Auch die anderen Modelle (Random Forest & Decision Tree) hatten Schwierigkeiten bei der Klasse „Unentschieden“ – was auch Sinn macht, denn diese Spiele sind am wenigsten vorhersehbar.
Die Ergebnisse aller Metriken der jeweiligen Modelle:
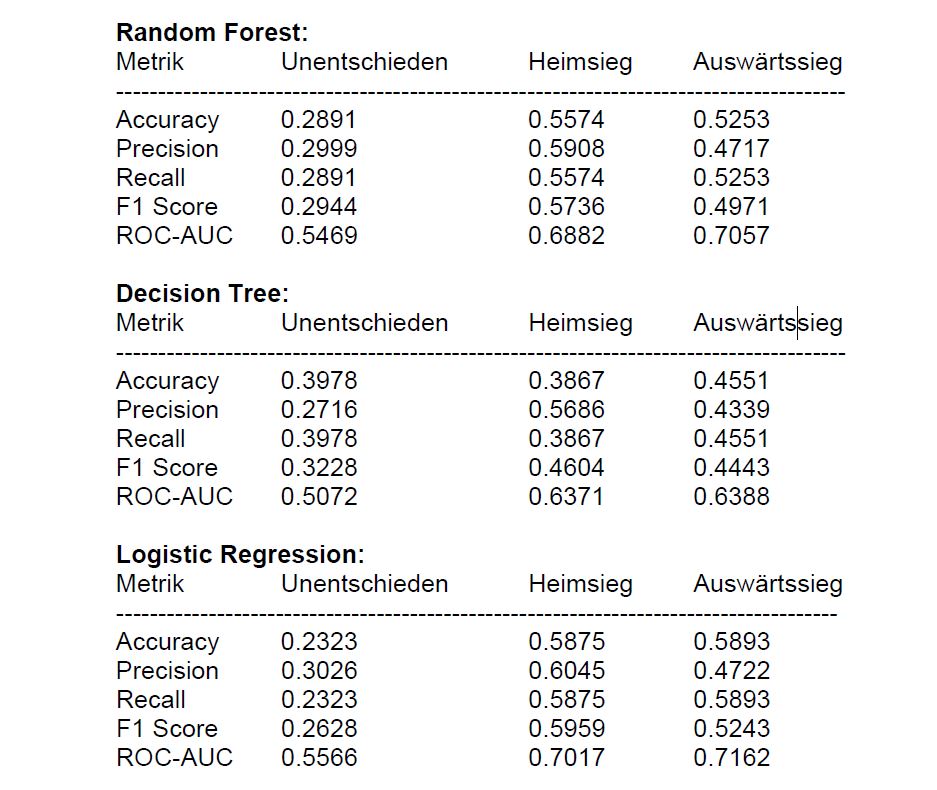
Definition der Metriken:
Evaluation Metrics for Logistic Regression: A Comprehensive Guide | by Deepak Biswakarma | Medium
Was bleibt hängen?
Das Projekt zeigt: Machine Learning kann bei der Spielvorhersage spannende Insights liefern – vor allem, wenn gute Daten und clevere Features im Spiel sind. Aber: Fussball bleibt unberechenbar. Verletzungen, Tagesform, rote Karten – all das lässt sich nur schwer in Zahlen fassen. Trotzdem ist es faszinierend zu sehen, wie viel Vorhersagekraft schon mit historischen Daten möglich ist.
Für die Zukunft denke ich über die Integration von Wetterdaten, Spielermetriken oder Social Media Stimmungen nach – denn im modernen Fussball gewinnt nicht nur der mit dem besseren Kader, sondern auch der mit den besseren Daten.