Durch welche Strategien kann man das Resilienzniveau seines Backupsystems steigern?
Der diesem Beitrag zugrundeliegende Use Case, ist ein Schweizer Enterprise Kunde.
Neben etwa drei dutzend Logistik- und Fertigungsstandorten in der CH, werden Services auch aus 4 DCs, sowie Azure und GCP an eine fünfstellige Nutzerschaft bereitgestellt.
Aufgrund der Marktbekanntheit und zunehmenden Sicherheitsvorfällen bei Wettbewerbern, hat man sich entschlossen, eine neue Backupumgebung für virtualisierte (vSphere), physische (Win, SLES) sowie DB-Workloads (MSSQL) zu implementieren. Auf die Resilienz der Lösung wurde ein besonderer Fokus gelegt.
-
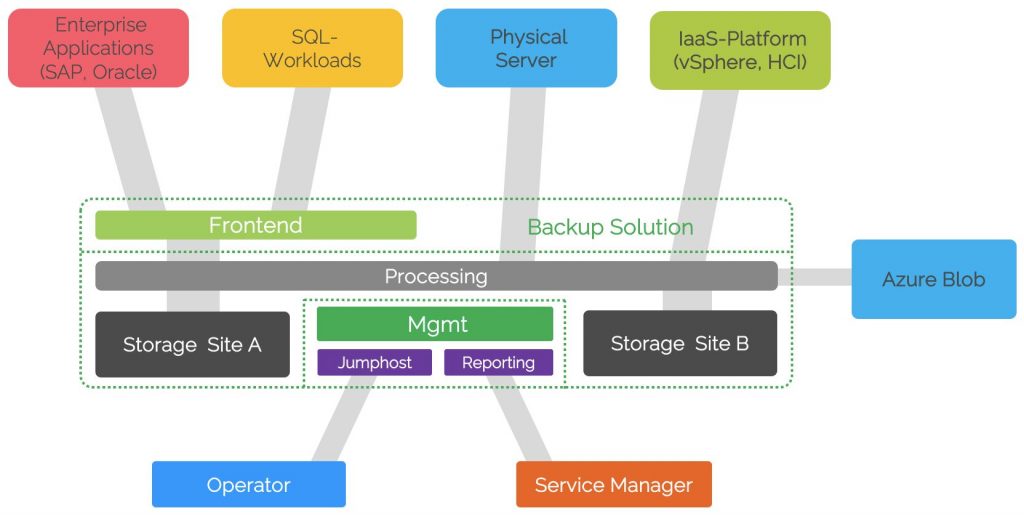
Zonierung
Eine Verteilung der Backupkomponenten in drei Zonen, welche durch performante Firewalls und ein granulares FW-Ruleset gehärtet werden, schützt grundsätzlich vor unerwünschten Verbindungen. Folgende Verteilung hat sich bewährt:
-
- Frontend: terminiert Verbindungen von zu sichernden Servern (Log-Shipping, Guest Interaction)
- Backend: enthält die Backupverarbeitung- und -speicherkomponenten
- Management: der Management-Server, Jumphosts und die Reporting-Systeme
-
Zugriffssteuerung
Um den operativen Zugriff auf die Backuplösung zu beschränken, sollte der direkte Zugriff von Clientsystemen und Servern unterbunden sein. Lediglich über eine redundante, auditfähige Jumphost/Stepstone-Infrastruktur sollte auf die Managementkonsole zugegriffen werden können. Dabei sollten dedizierte User (PAM) und MFA-Massnahmen eingesetzt werden.
-
Immutability
Eine der grössten Ängste eines digitalisierten Unternehmens kann bei einem erfolgreichen Ransomwareangriff wahr werden: Die gesicherten Daten sind im Backupsystem verschlüsselt und können die ebenfalls kryptierten Produktivdaten nicht ersetzen.
Immutability, Retention Lock, WORM sind hier gängige Begriffe, welche grundlegend die selbe Schutzmassnahme beschreiben: Das „sperren“ von gesicherten Daten durch Zeitstempel und eine segregierte Enforcement-Rolle. Daten werden dabei z.B. ins Dateisystem des Backup-Backends geschrieben und sind bis zum Ablauf einer anfangs definierten Sperrfrist nicht manipulierbar. Dies schränkt die Erfolgsaussichten eines Cryptolockers erheblich ein, wenn er versucht Backupdaten zu verschlüsseln.
-
Datenredundanz
Einmal ist keinmal – dieser alte Redundanzgrundsatz greift auch bei der Aufbewahrung von Backupkopien.
Dabei empfiehlt sich ein, aus der Applikationskritikalität abgeleitetes SLA-Model. Demnach könnten bspw. Test-Daten nur einmal, Qual- und Prod-Daten zweimal und Mission-Critical-Daten dreimal aufbewahrt werden. Die Anzahl der Kopien und deren Orte ist praktisch nur durch den Speicher- und Transitbedarf und deren entsprechende Kosten begrenzt.
Als eine gute Lösung für die Offsite-Sicherung hat sich hierbei die Integration von Cloud-Objectstorage bewährt (Blob, S3), wobei dort ebenfalls Hyperscaler-seitig Immutability angeboten wird.
Wenn Cloud-Integrationen nicht möglich sind, sollte mindestens eine Kopie in eine zweite Faultdomain (Netzwerk-Segment, Standort, Serverraum etc.) geschrieben werden, um den Ausfall des Primärsystems kompensieren zu können.
-
Segregation of Duties
Rache, Lebenskrise, Fehlbedienung – oft kann ein einzelner „Innentäter“, unbewusst oder absichtlich („Bad Admin„) grossen Schaden innerhalb der Backupinfrastruktur und deren Daten anrichten.
Segregation of Duties beschreibt ein Konzept, bei dem voneinander abhängige Service-Agenturen bestimmte Rechte innerhalb eines Gesamtprozesses haben und auf Zusammenarbeit angewiesen sind.
Dabei können gewisse Vorgänge bspw. nur im 4-Augen-Prinzip erledigt werden. Weiterhin können verschiedene Teams innerhalb der Backuplandschaft für HW, die Betriebssysteme und die Backup-Software verantwortlich sein. Dadurch kann kein einzelner Backup-Operator Daten aus dem System löschen, ohne Unterstützung durch Kollegen zu erhalten.
-
Service-User
Wer sichern will, braucht Rechte auf den Quellsystemen (App-Server, DBs etc.).
Da Backup tief in die Systeme ergreift, besitzen Service-User oftmals Admin-gleiche Berechtigungen. Hier gilt es die „Durschschlagstiefe“ eines möglicherweise kompromittierten Service-Users zu begrenzen. Ein Service-User, sollte nur in einem begrenzten Scope nutzbar sein ( z.B. ein DC, nur SQL-System, nur Gewissen OS-Versionen, nur physische Server, nur eine Applikation etc.). So gilt es abzuwägen, ob man dadurch 2, 20 oder 100 Service-User managen muss.
Stichwort „managen“ – es empfiehlt sich eine Passwortrotationspolicy von z.B. 2 Monaten zu etablieren
Diesem Thema begegnet man im Microsoft-Umfeld mit dem Konzept der „Group Managed Service Accounts„. Hierzu werden Serviceuserobjekte AD-seitig durch OUs und Gruppen gesteuert. Die dabei alle 30 Tage selbsterneuerten Passwörter können vom Backup-Operator nicht gelesen werden, wodurch deren Kompromittierbarkeit drastisch reduziert wird.
Das GMSA-Konzept wird hier klar empfohlen, um das Backupsystem z.B. gegen eine Windows-Server- oder MSSQL-Landschaft zu authentifizieren.
-
Performance
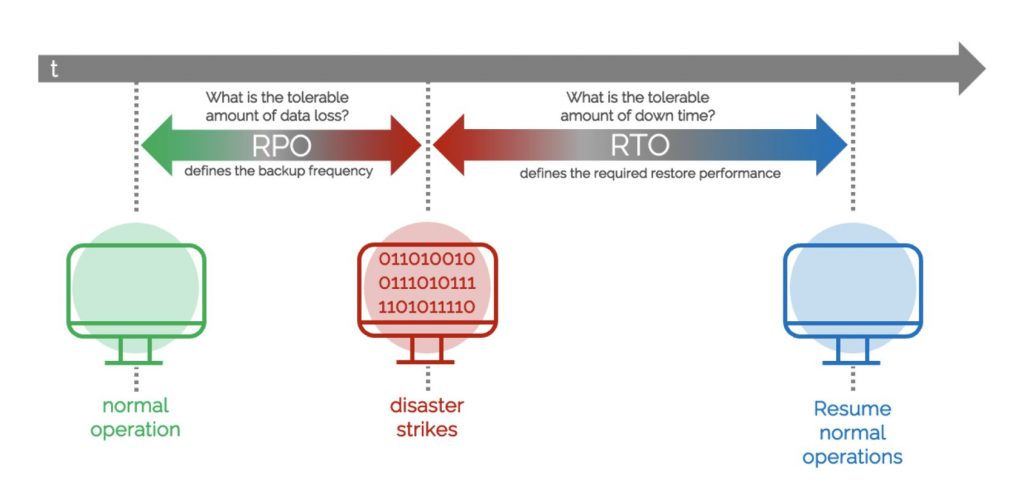
Das Business definiert die maximal erträgliche Zeit, bis Systeme wieder nutzbar sein müssen. Dieser Zeitraum schmilzt jedoch schnell ab, wenn man Analysen und Troubleshooting vorweg, sowie Anpassungen und Testing nach dem Restore abzieht. Oftmals werden fantastische Zahlen wie „RTO 4h“ angegeben, wovon in der Praxis etwa 2h verbleiben, um wirklich etwas „zurückzukopieren“. Demnach sollten diese 2h gut genutzt werden, um soviel Daten wie möglich „über den Draht „zu bekommen.
Hohe Sequenzielle Lesegeschwindigkeiten können mit grossen spindelbasierten Speichersystemen in der Regel zu einem günstigen pro-TB-Preis realisiert werden. Zunehmend setzt man auch auf hochperformanten NVMe-basierten Backupspeicher, welcher wesentlich höhere Datenraten im konkurrenzierenden Zugriff (gleichzeitige Backup-, Copy- und Restore Jobs) erlaubt.
-
Validierung
Vertrauen ist gut, Kontrolle ist besser.
Aktuelle Enterprise-Backup-Lösungen bieten Möglichkeiten eines automatisierten Recovery-Testings. Dabei können definierte Systeme Job-basiert in einer Sandbox angestartet werden und neben Heartbeat und Ping auch Service-Responses abgefragt werden.
Dies kann rollierend bspw. Nachts nach dem eigentlichen Backup automatisch validiert werden, um ein genaues Verständnis über die Wiederherstellbarkeit der eben gesicherten Systeme zu erhalten.
Fazit
Wenn man einen Restore braucht, braucht man ihn in der Regel dringend.
Man muss sich somit darauf verlassen können, dass das Backupsystem auch in einer Krise bestimmungsgemäss funktioniert.
Die oben genannten Massnahmen – einzeln oder als Ganzes – sollen Denkanstösse zur Erhöhung des Resilienzniveaus bieten.
Oftmals haben die von Herstellern propagierten Features evolutionär das Lab-Stadium nicht verlassen und sind in realen Szenarien nur selten anzutreffen.
Alle oben genannten Vorschläge jedoch, sind bereits erfolgreich im Einsatz.