
«Big Data» wird heute als Fundament von Künstlicher Intelligenz, Machine Learning oder selbstfahrenden Autos häufig schon fast als gegeben betrachtet. Trotzdem bleibt es oft schwierig, sich eine klare Vorstellung über die Mengen der dabei verarbeiteten Daten machen zu können.
Mit dem Ziel, das Gefühl für die Grössenverhältnisse in «Big Data» zu schärfen, wird uns dieser Beitrag die Einheiten der digitalen Datenspeicherung Schritt für Schritt näher bringen und uns dabei bis an den Rand des Universums begleiten und wieder zurück.
Häsch mer en Stutz?
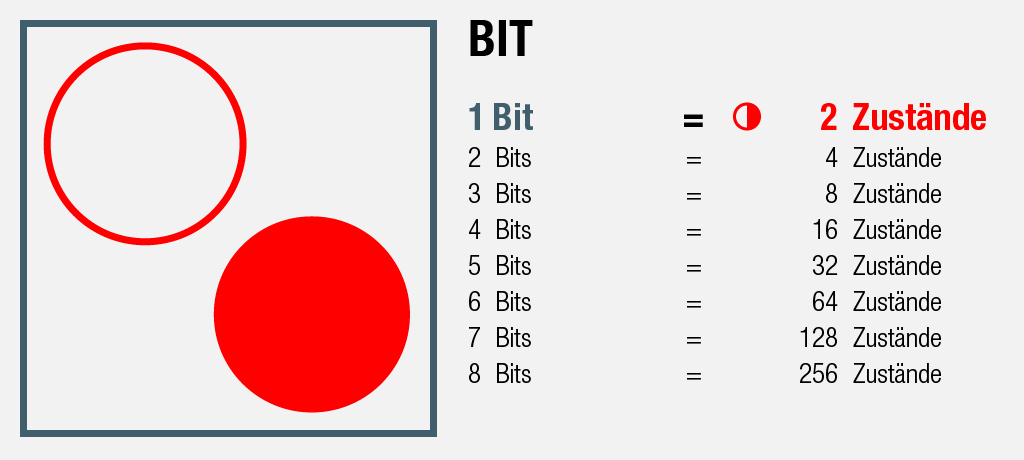
2 Zustände ≙ 1 Bit

Betrachten wir dieses kanadische 20$-Geldstück: Mit jedem Münzwurf ist die Chance, Kopf oder Zahl (oder in diesem Fall Walfische) zu erhalten, jeweils 50%.
Kopf oder Zahl – der Informationsgehalt dieser zwei möglichen Zustände entspricht (im klassischen Sinn, wir ignorieren Quantencomputer) einem «Binary Digit», kurz Bit . Experimentiert man mit zwei Münzen, eröffnet sich ein Informationsraum von 2 Bits, also 4 Zuständen. Möchte man etwas mehr Geld in die Hand nehmen, erhält man mit 3 Münzen 8 mögliche Zustände. Mit 8 Bits sind es gar 256. In einem Computer-Prozessor würde man anstelle von «Kopf» und «Zahl» von «1» und «0» sprechen (man stelle sich ein Lämpchen in einem Schaltkreis vor, das brennt oder eben nicht).
Dieses relativ einfache Konzept des Bits soll an dieser Stelle ausreichen, um digitale Speichermengen zu verstehen. Die riesigen Zahlen, denen wir zur Quantifizierung dieser Volumina begegnen werden, verlangen jedoch etwas mehr intellektuelle Gymnastik.
Bitte ein Byte
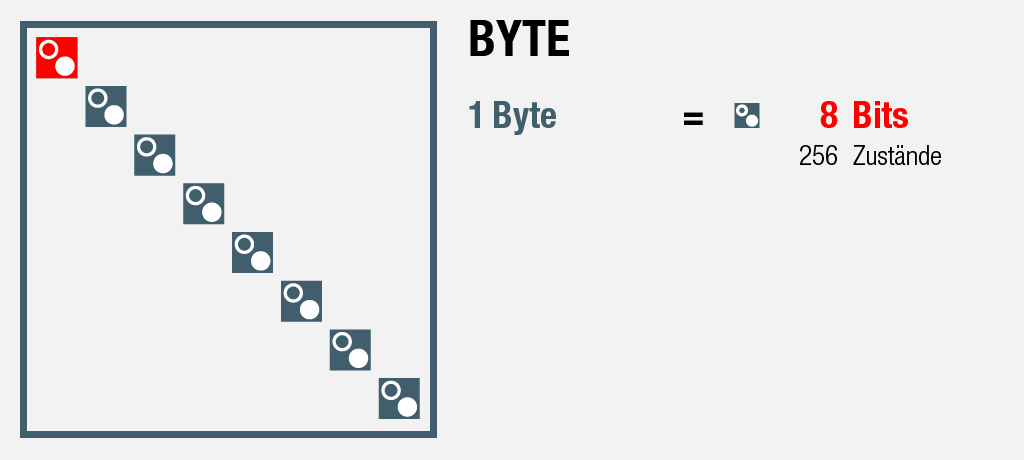
8 Bits = 1 Byte
Bleiben wir nun aber bei den 8 Bits mit ihren insgesamt 256 möglichen Zuständen: Die Einheit dafür ist ein Byte.
Dieser 1-Byte Speicher ist gross genug, um 1 (Schrift-) Zeichen in Computersprache zu codieren, was sich u.a. die Zeichencodierung Codepage 437, der Original-Zeichensatz von IBM-Personal Computers ab 1981 (auch: «DOS Latin US») zu Nutze macht [1]. In diesem Standard sind wiederum 256 unterschiedliche Zeichen definiert.
Diese 256 Zeichen sind noch so überschaubar, dass sie auf dem folgenden Screenshot des dazugehörigen Wikipedia-Eintrages Platz finden:
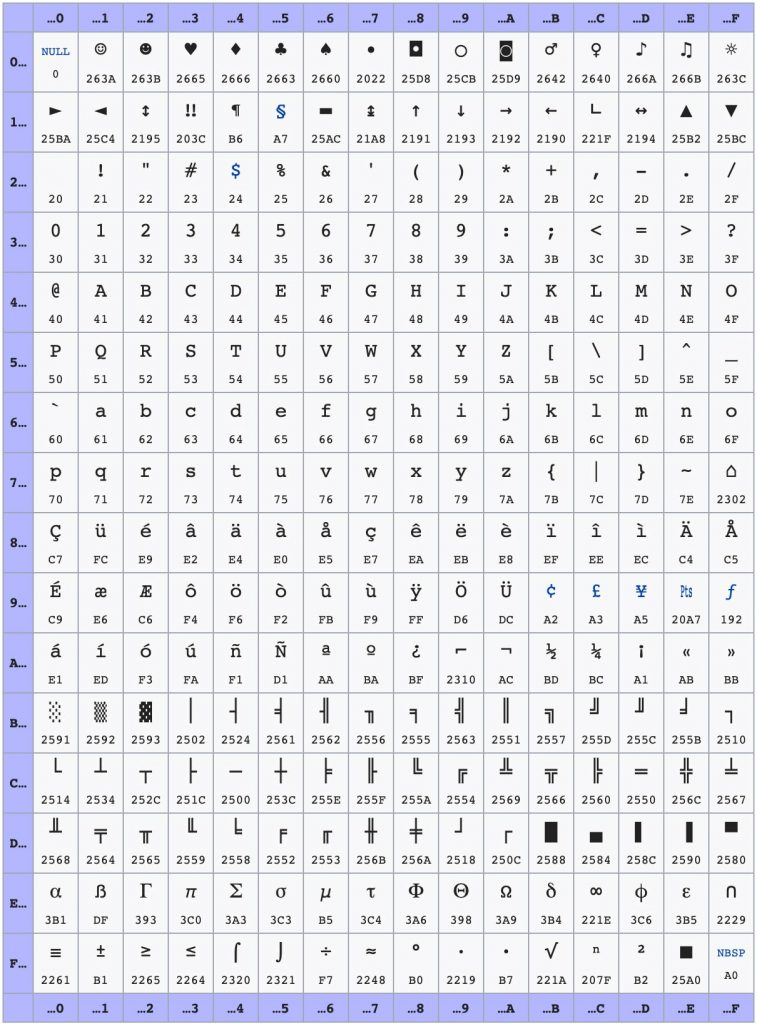
Dieses JPEG in mittlerer Qualität benötigt etwa 256 Kilobytes Speicher, also ziemlich genau 1000-mal mehr als die entsprechende Zeichenfolge in Codepage 437.
Call me Ishmael
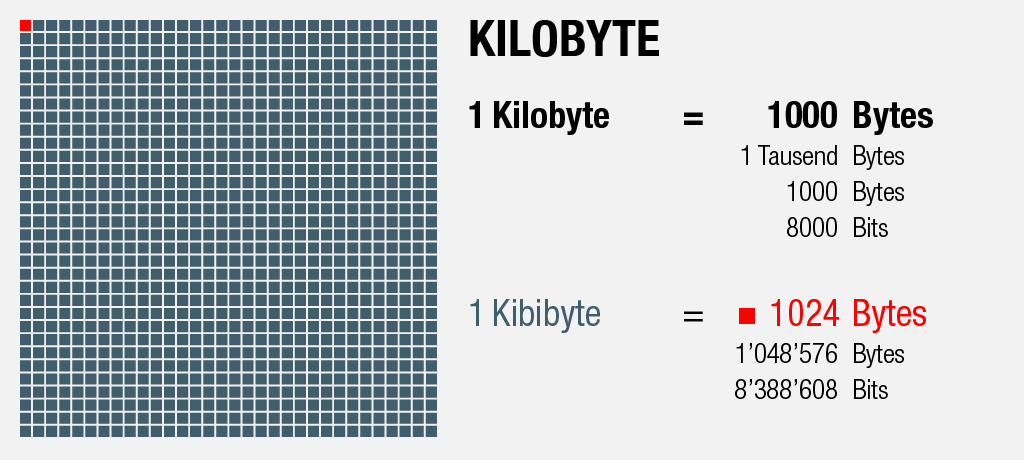
1000 Bytes = 1 Kilobyte
Um mehr als 256 Zeichen darstellen zu können, gehen wir einen Schritt weiter: Mit 1000 dieser Bytes erhält man, wie der Name schon sagt, ein Kilobyte.
«Call me Ishmael» – der erste Satz des ersten Kapitels aus «Moby Dick» gilt als einer der bekanntesten und besten Einleitungen der Weltliteratur. Grund genug, den folgenden Ausschnitt aus Herman Melvilles Klassiker als Beispiel heranzuziehen.
Er entspricht 1024 Bytes, würde man ihn in einem reinen Textfile (ohne Metadaten und dergleichen) im Codepage 437 Format abspeichern [2]:
Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world. It is a way I have of driving off the spleen and regulating the circulation. Whenever I find myself growing grim about the mouth; whenever it is a damp, drizzly November in my soul; whenever I find myself involuntarily pausing before coffin warehouses, and bringing up the rear of every funeral I meet; and especially whenever my hypos get such an upper hand of me, that it requires a strong moral principle to prevent me from deliberately stepping into the street, and methodically knocking people’s hats off—then, I account it high time to get to sea as soon as I can. This is my substitute for pistol and ball. With a philosophical flourish Cato throws himself upon his sword; I quietly take to the ship. There is nothing surprising in this. If they but knew it, almost al
Jetzt kommt’s ganz Dick!
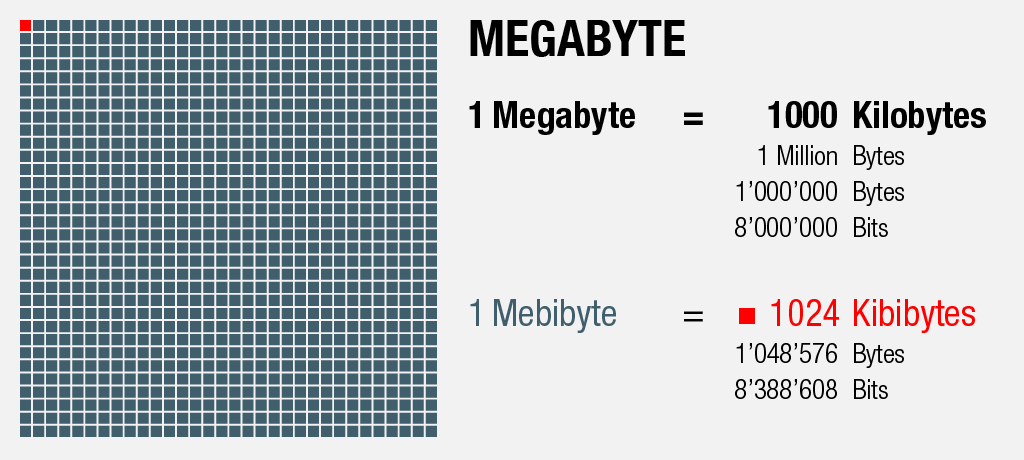
1000 Kilobytes = 1 Megabyte
Die komplette Geschichte von «Moby Dick» mit 135 Kapiteln plus Pro- und Epilog bringen uns auf einen Speicherbedarf von ca. 1200 Kilobytes – etwas mehr als einem Megabyte – was wiederum dem benötigten Datenvolumen entspricht, den folgenden Scan einer Seite der U.S.-Erstausgabe als schwach komprimiertes JPEG zu speichern:

Netflix and chill
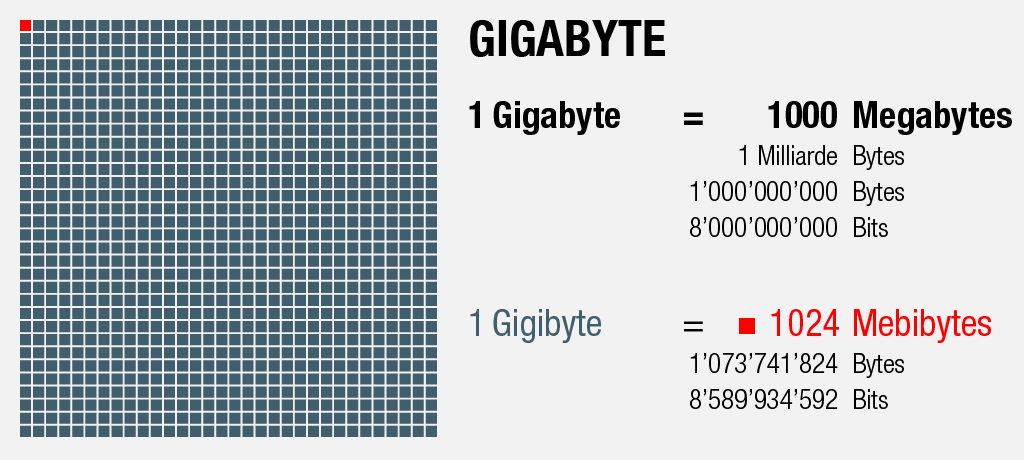
1000 Megabytes = 1 Gigabyte
Speziell der jüngeren Generation (die in der diesjährigen Pisa-Studie in der Kategorie Textverständnis nur mässig abgeschnitten hat) sei dieser Abschnitt gewidmet [3]:
Statt sich «Moby Dick» in Buchform zu erarbeiten, könnte man sich mit einem Gigabyte den Film in dürftiger Qualität in digital Video (ca. 720p, je nach Format und Komprimierung) herunterladen.
Etwas anspruchsvollere Filmfans gönnen sich stattdessen das Abenteuer auf einer Blu-Ray Disc, die mit einem Speicherplatz von 25 Gigabytes ein sehr anständiges Filmerlebnis in 1080p Bildauflösung samt Extras liefert. Oder sie geniessen den Film auf Netflix in HD, wobei ca. 3 Gigabytes pro Stunde gestreamt werden [4].

We are all made of Stars
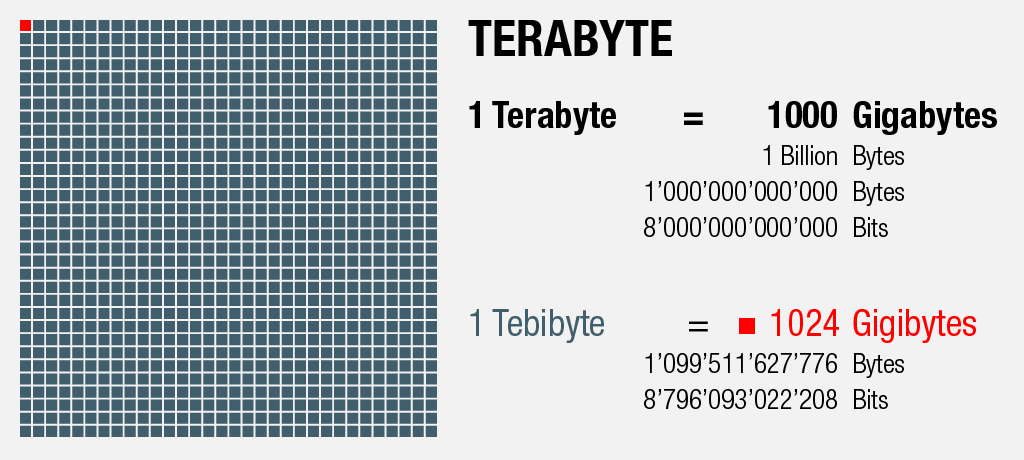
1000 Gigabytes = 1 Terabyte
Auf Sterne und das Universum kommen wir später noch zu sprechen, nun wenden wir uns jedoch erst einem handelsüblichen Laptop zu, der im Jahr 2019 gut und gerne mit einer etwa einem oder zwei Terabyte grossen Festplatte geliefert wird.
Ein Laptop, wie ihn vielleicht der U.S.-amerikanische Sänger, Gitarrist, DJ und Musikproduzent Moby heute noch benutzt. Für alle diejenigen, die den DJ nicht mehr kennen sollten, hier das Musikvideo seines wohl bekanntesten Hits:
Natürlich wurde Moby nicht ganz zufällig ausgewählt, denn Moby – mit bürgerlichem Namen Richard Melville Hall – ist der Ur-Ur-Grossneffe von Herman Melville [5], dem Autor von «Moby Dick», was seinen Künstlernamen und die Erwähnung in diesem Artikel erklären dürfte.
Um nun zurück auf die Sterne zu kommen: Nimmt man 10 dieser Terabytes, entspricht dies etwa der Menge Daten, die das Hubble Space Teleskop in einem Jahr liefert [6]. Und 480 Terabytes würde eine digitale Bibliothek benötigen, die nicht nur Herman Melvilles gesammelte Werke, sondern sämtliche je katalogisierten Büchern umfassen würde [7].
There’s always a bigger fish
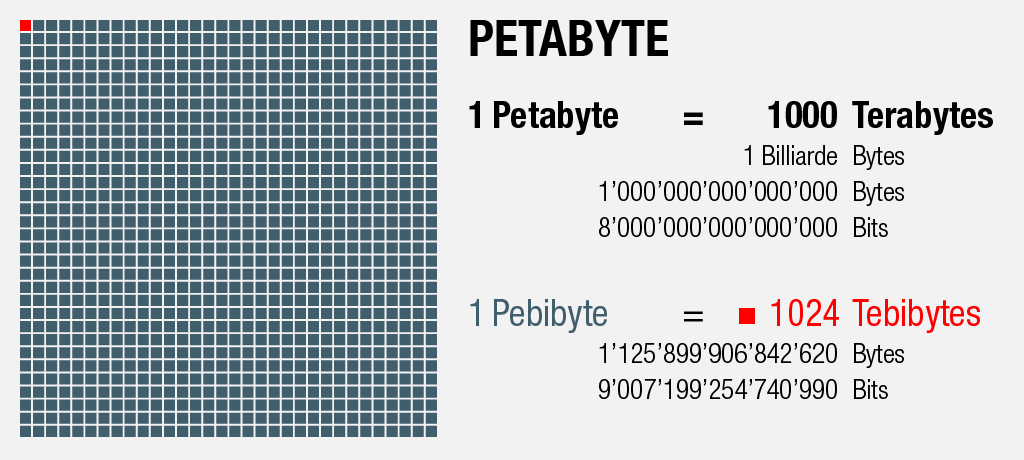
1000 Terabytes = 1 Petabyte
Leider müssen wir uns an dieser Stelle trotzdem fürs Erste vom Thema Walfisch verabschieden.
Bleiben wir stattdessen bei der Astronomie: 2019 wurde die grösste je produzierte optische Linse für die ca. 168 Millionen Dollar teure, 3,2-Gigapixel-Kamera (was ca. einem halben Basketball-Feld voller 4k TVs entspricht) des Large Synoptic Survey Telescope (LSST) geliefert. Dieses Weltraumteleskop soll nach mehr als 10 Jahren Entwicklungszeit im Jahr 2022 fertig gestellt werden und an seinem Standort im nördlichen Chile fähig sein, den zugänglichen südlichen Nachthimmel während drei Nächten komplett zu fotografieren und dies während zehn Jahren tun.
Dabei werden im ersten Jahr mehr Daten gesammelt werden, als bis dann je von sämtlichen Teleskopen überhaupt zusammengetragen wurden: Pro Jahr durchschnittlich 6 Petabytes oder 20 Terabytes pro Nacht [8][9][10].
Man könnte dabei also pro Nacht 10 bis 20 von Mobys Laptops mit Daten füllen. Andere physikalische Untersuchungen sind bei ihrer Arbeit nicht ganz so genügsam, wie z.B. die Experimente des Teilchenbeschleunigers am CERN in Genf, die total einen Datenfluss von 25 Petabytes pro Sekunde produzieren sollen [11]. Was erstaunlicherweise nur etwa 10 mal mehr ist, als was das menschliche Gehirn gemäss höchsten Schätzungen überhaupt speichern kann (2,5 PB) [12].
Und nun: «Wal-Mart».
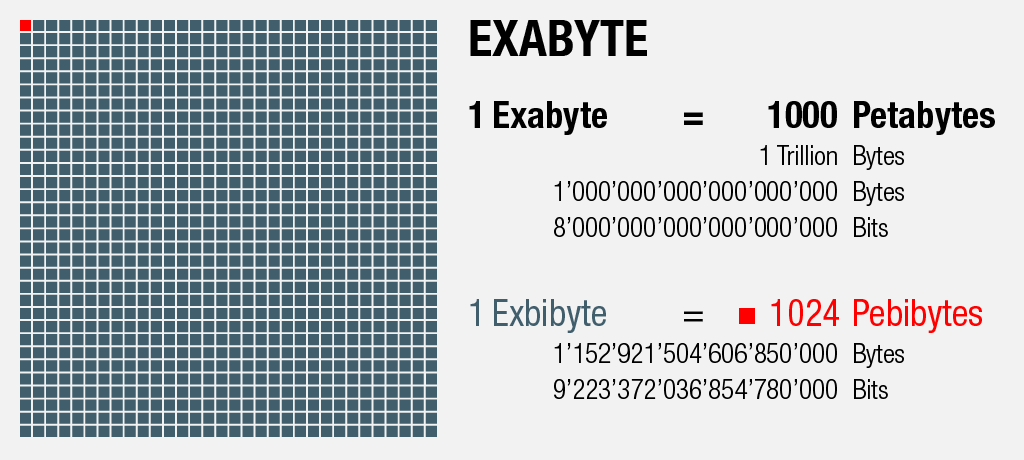
1000 Petabytes = 1 Exabyte
Der international tätige U.S.-Einzelhandelskonzern Walmart sammelt jede Stunde 2,5 Petabytes an Daten von seinen mehr als 1 Million Kunden [13]. Das sind in 5 Wochen ca. 1000 Petabytes oder 1 Exabyte an Daten (2,5×12×7×5=1050 PB).
Während Google 40’000 Suchanfragen pro Sekunde verarbeitet und auf Facebook täglich 300 Millionen Fotos heraufgeladen werden (2018) [13], sind wir nun bei Datenmengen im Exa- und Zettabyte-Bereich angelangt, wofür der Begriff «Big Data» wohl ohne zu übertreiben verwendet werden darf.
We’re gonna need a bigger boat!
1000 Exabytes = 1 Zettabyte
Bei soviel Online-Aktivität erstaunt es wenig, dass der gesamte Internet-Datenverkehr für das Jahr 2016 auf ca. 1,1 Zettabytes geschätzt wurde [14].
Die weltweit total generierte Menge an digitalen Daten überstieg schon damals die Menge der tatsächlich zu speichernden Daten und den zur Verfügung stehenden Speicherplatz:
Während 2013 noch etwa 33% aller generierten digitalen Daten hätten gespeichert werden können [15], betrug 2018 die globale Datenmenge 33 Zettabytes [16], wovon nur ein Bruchteil persistiert wurde.
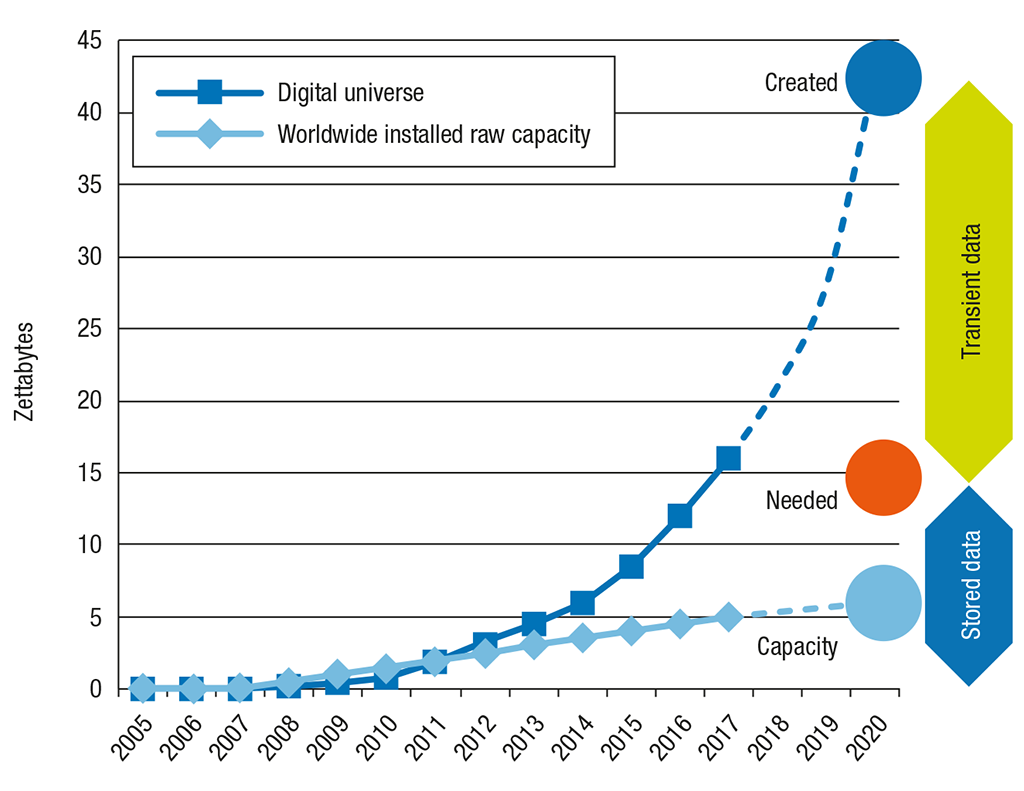
Wie ein Report der International Data Corporation (IDC) errechnet, wird die «globale Datensphäre» im Jahr 2020 bereits 44 Zettabytes betragen (163 ZB in 2025), wovon aber nur 15% auf Dauer gespeichert werden können. Der Datenspeicher-Hersteller Seagate bestätigt, dass sich dieses Missverhältnis von generierter Datenmenge und dem zur Verfügung stehenden Speicherplatz in Zukunft noch weiter vergrössern wird [15].
A New Hope
1000 Zettabytes = 1 Yottabyte
Die grössten Hoffnungen, diese Datenkapazitäts-Lücke in unserer digitalen Zukunft der Yottabytes wieder zu verkleinern, liegen in neuen Speicher-Technologien, welche die klassischen magnetischen Datenspeicher ergänzen sollen:
Moderne, optische («nano-photonische») Speicher-Discs könnten bald Kapazitäten im 1-Petabyte-Bereich erreichen und vielversprechende Versuchsanordnungen in der biomolekularen Datenspeicherung nähern sich mittlerweile einer Datendichte von bis zu 214 Petabytes pro Gramm DNA (DNS, Desoxyribonukleinsäure). [15]
Starsailor
Absolute Grenzen der Datenspeicherung
Werfen wir zum Abschluss sämtliche praktischen Anwendungen über Bord unseres bildhaften Walfängers, schrumpft sogar das Yottabyte auf mikroskopische Grösse:
Im Jahr 2002 errechnete der U.S.-amerikanische Informatiker und Physiker Seth Lloyd die Informationsmenge, die das beobachtbare Universum theoretisch aufnehmen könnte [17].
Die Anzahl Bits, auf die er dabei kam, entsprechen einer 1 mit 90 Nullen:
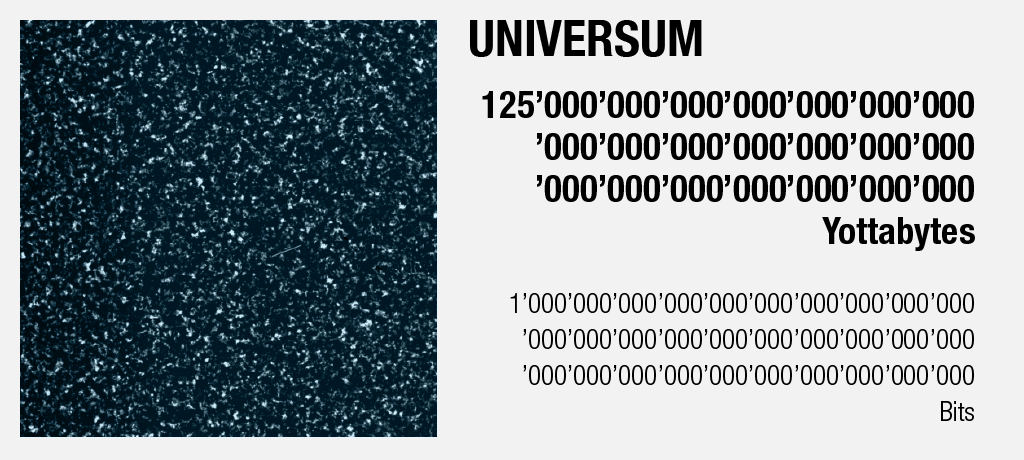
Bevor wir uns aber gänzlich in den unendlichen Weiten des Weltalls verlieren, hängen wir gleich noch einmal 10 Nullen an diese Zahl, was uns schliesslich zurück zum Thema «Big Data» führen wird:
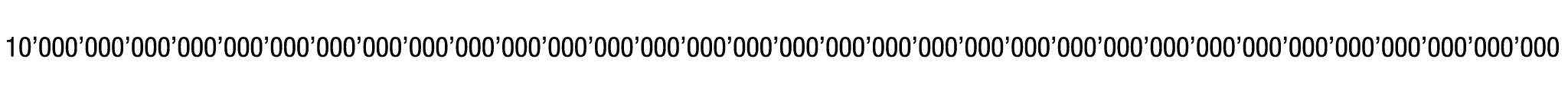
Der systematische deutsche Name dieser Zahl (einer 1 mit 100 Nullen) ist zehn Sexdezilliarden – und obwohl für sie kaum eine praktische Anwendung existiert, wurde sie aufgrund ihres Spitznamens, der 1938 durch den amerikanischen Mathematiker Edward Kasner etabliert wurde, bekannt: «Googol». [18]
Diese Wortschöpfung diente als Inspiration für den Namen der Suchmaschine Google. Der Begriff sollte die immense Menge der von ihr zu indexierenden Webseiten widerspiegeln. [19]
Betrachtet man Googles Entwicklung zu einem der innovativsten Technologie-Unternehmen der vergangenen Jahre [20], erscheint dieser ambitiöse Name rückblickend als gar nicht mal so hochgegriffen:
Längst hat sich Google als De-Facto-Standard etabliert und ist zum fast unverzichtbaren Hilfsmittel bei der Navigation im riesigen Daten-Ozean namens World Wide Web geworden.
Den sprichwörtlichen «Weissen Wal» findet man damit zwar nicht immer – die Abbildung einiger Weisswale auf einem kanadischen 20$-Geldstück ist jedoch schon mal ein ganz guter Anfang.
In diesem Sinne: Ahoi!
Appendix: Die Speichermengen im Vergleich
An dieser Stelle sei erwähnt, dass zwei verwandte Bezeichnungs-Muster für Speichergrössen existieren: Während im Sprachgebrauch meist mit einfacher fassbaren Tausenderschritten gerechnet wird, verändern sich die Grössenverhältnisse für Hard- und Software aufgrund ihres binären Charakters nicht in Potenzen von 10, sondern in Potenzen von 2.


Alle Grafiken: Raphael Röthlin
Quellennachweise
- 1. https://de.wikipedia.org/wiki/Codepage_437. Abgerufen am 6.12.2019.
- 2. https://www.gutenberg.org/files/2701/2701-h/2701-h.htm. Abgerufen am 6.12.2019.
- 3. https://www.blick.ch/news/neue-pisa-studie-schweizer-schueler-in-allen-faechern-schlechter-geworden-id15645438.html Abgerufen am 6.12.2019.
- 4. https://help.netflix.com/en/node/87. Abgerufen am 6.12.2019.
- 5. https://de.wikipedia.org/wiki/Moby. Abgerufen am 6.12.2019.
- 6. https://www.nasa.gov/mission_pages/hubble/story/index.html. Abgerufen am 7.12.2019.
- 7. Krzanowski, R. (2019). New dark age: Technology and the end of future. Information, Communication & Society, 22 (9), 1352–1359. https://doi.org/10.1080/1369118X.2019.1610026
- 8. https://www.lsst.org/about. Abgerufen am 6.12.2019.
- 9. https://www.youtube.com/watch?v=33UMkPe93Ko. Abgerufen am 6.12.2019.
- 10. https://www.dpreview.com/news/7079598727/the-world-s-largest-optical-lens-has-been-delivered-for-massive-3-2-gigapixel-digital-camera. Abgerufen am 6.12.2019.
- 11. https://home.cern/science/computing/processing-what-record. Abgerufen am 7.12.2019.
- 12. https://slate.com/technology/2012/04/north-koreas-2-mb-of-knowledge-taunt-how-many-megabytes-does-the-human-brain-hold.html. Abgerufen am 7.12.2019.
- 13. Hariri, R., Fredericks, E., & Bowers, K. (2019). Uncertainty in big data analytics: Survey, opportunities, and challenges. Journal of Big Data, 6 (1), 1–16. https://doi.org/10.1186/s40537-019-0206-3
- 14. Cisco (2015). The Zettabyte Era: Trends and Analysis. Cisco White Paper. https://files.ifi.uzh.ch/hilty/t/Literature_by_RQs/RQ%20102/2015_Cisco_Zettabyte_Era.pdf. Abgerufen am 6.12.2019.
- 15. Bhat, W. A. (2018). Is a Data-Capacity Gap Inevitable in Big Data Storage? Computer, 51 (9), 54–62. https://doi.org/10.1109/MC.2018.3620975
- 16. Reinsel, D., Gantz, J., & Rydning, J. (2018). Data Age 2025. The Digitization of the World. IDC Whitepaper. https://www.seagate.com/de/de/our-story/data-age-2025/. Abgerufen am 6.12.2019.
- 17. Lloyd, S. (2002). Computational capacity of the universe. Physical Review Letters, 88 (23), 237901. https://doi.org/10.1103/PhysRevLett.88.237901
- 18. https://de.wikipedia.org/wiki/Googol. Abgerufen am 3.1.2020.
- 19. https://www.quora.com/How-did-Google-get-its-name. Abgerufen am 3.1.2020.
- 20. https://www.forbes.com/sites/louiscolumbus/2019/03/24/the-most-innovative-companies-of-2019-according-to-bcg/#1093d594486d. Abgerufen am 3.1.2020.
Das war SUPER erklärt!
Sehr unterhaltsam!