In meinem Arbeitsalltag war ich bisher vor allem mit Qlik Sense unterwegs. Anfangs wirkt es praktisch, Transformation und Visualisierung im gleichen Tool zu bauen, doch schnell wird die Logik unübersichtlich, schwer wartbar und ohne Versionskontrolle ziemlich riskant. Dazu kommt, dass sich Datenflüsse nur schwer nachvollziehen lassen, was die Zusammenarbeit und Weiterentwicklung spürbar erschwert.
Mit einem kleinen Projekt, das ich auf Github öffentlich freigegeben habe, möchte ich herausfinden, ob dbt meinen Workflow verbessern kann und hier im Blog über meine Erfahrungen berichten.
Was ist dbt?
Dbt kann sowohl lokal (dbt core) als auch in der Cloud (dbt platform) installiert und ausgeführt werden. Das folgende Bild aus dem offiziellen Github dbt Core Repository zeigt, wo sich dbt in einer modernen ELT Architektur bewegt. Es orientiert sich an bewährten Prinzipien aus dem Software Engineering wie Versionierung, Portabilität, Modularität, CI/CD und einer durchgängigen Dokumentation. All das bietet eine saubere und moderne Basis für datengetriebene Projekte.
Wie funktioniert dbt?
Dbt wird dem folgenden Command in einer Python Umgebung installiert:python -m pip install dbt-core
Die ganze Projekt Struktur wird mit dem Command dbt init generiert. Anschliessend können im profiles.yml die Datenbank Verbindung angepasst werden. Die wichtigste generierte Datei ist jedoch dbt_project.yml welches die Projekt Struktur definiert und beschreibt wie die Daten ( Materializations Types) in der Datenbank abgelegt werden.
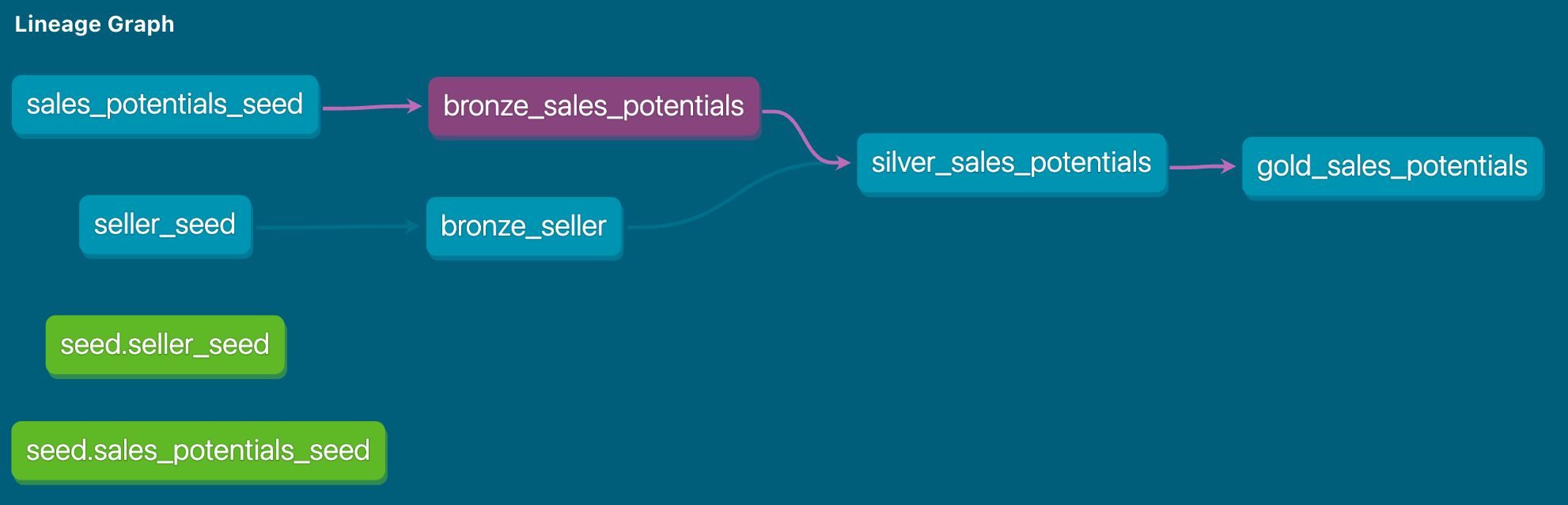
Der spannendste Ordner in einem dbt Projekt ist Models. Hier passiert die eigentliche Magie, denn in diesen Dateien steckt der grösste Teil der Transformationslogik. Alles dreht sich um sauber strukturierte Select Statements, die als .sql Dateien gespeichert werden und Schritt für Schritt die Daten transformieren.
Zudem wird mithilfe von Jinja das dbt Projekt zu einer Art Programmierumgebung für SQL, welches es ermöglicht Funktionen zu nutzen die in normalem SQL nicht möglich wären.
Highlights
Was kann dbt nicht?
Dbt konzentriert sich im ELT Prozess, ausschliesslich auf die Transformation. Es besitzt keine Konnektoren, um Daten aus Quellsystemen zu extrahieren oder zu laden, sondern wird erst eingesetzt, wenn die Daten bereits im Data Warehouse oder Data Lake liegen.
Fazit
Dbt ist kein klassisches Low-Code/No-Code Werkzeug, in dem man sich schnell zusammenklickt, was man braucht. Stattdessen handelt es sich um ein Framework, das ein gewisses technisches Grundverständnis voraussetzt und eine klare Struktur im Datenengineering vorgibt. Gerade am Anfang wirkt die Lernkurve, im Vergleich zu anderen Tools, spürbar steiler.
Doch genau hier steckt die grosse Stärke von dbt. Im Kern arbeitet man einfach mit SQL als Code. Dadurch lassen sich auch komplexe Transformationen sauber versionieren, testen und langfristig deutlich besser warten. Wer diesen Schwerpunkt auf der Entwicklung zunächst als Hürde empfindet, merkt später schnell, wie sehr er sich auszahlt. Denn am Ende entsteht eine Datenpipeline, die transparent ist und sich ohne Abhängigkeit von einem bestimmten Tool weiterentwickeln lässt.
Vergleicht man diese Vorteile mit den Transformationsfunktionen in Qlik Sense, wird schnell klar, welche Vorteile dbt bietet. Kurz gesagt, dbt bringt Software Engineering Prinzipien in die Datenwelt und wird damit zum echten Gamechanger für nachhaltige und robuste Datenpipelines.
Weiterführende Links
Dieser Blogbeitrag wurde mit Unterstützung von KI optimiert.