
Du stehst vor der Herausforderung Daten aus SAP BW mit Python oder R auszuwerten und nutzt dafür eine Cloud-Umgebung? Dieser Blog gibt dir Antworten darauf, wie deine SAP Objekte modelliert werden müssen, was bei Zugriffsberechtigungen zu berücksichtigen ist und wie du es schaffst deine Ergebnisse aus der Cloud in ein SAP BW zu schreiben.
In einer Data Warehouse Architektur, in dessen Mittelpunkt ein SAP BW steht, stellt sich zunehmend die Frage, wie Daten für Umgebungen bereitgestellt werden können, in denen R oder Python als Programmiersprache zur Verfügung stehen. Dies weil R oder Python für komplexe mathematische oder statistische Modelle sehr viel besser geeignet sind als beispielsweise SQL oder ABAP. Eine mögliche Architektur könnte hierfür wie folgt aussehen.
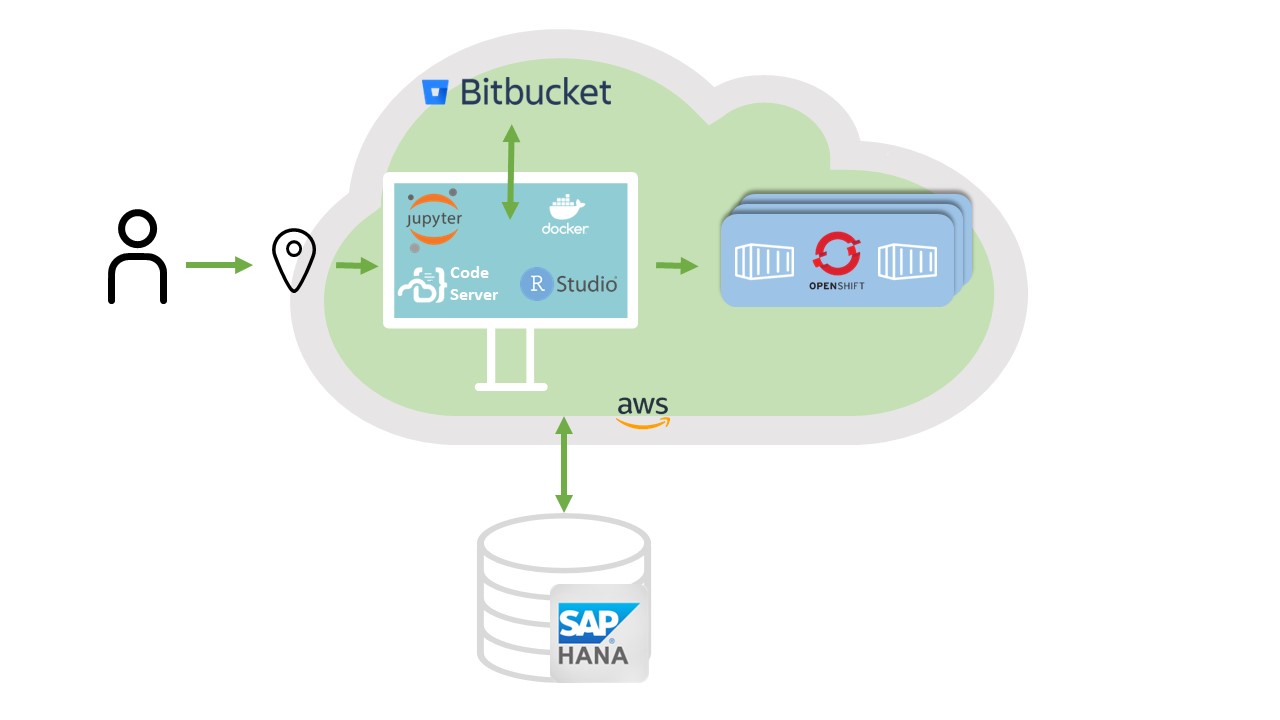
1. Datenbereitstellung in SAP BW on HANA
Die Daten werden über Calculation Views (CV) bereitgestellt. D.h. du kannst die Datengrundlage über HANA-Native Möglichkeiten modellieren. Alle gängigen BW-Objekte, wie Active DataStore Obects (ADSO) etc. können genutzt werden. Da es für einige Code-Sprachen schwierig ist mit Nummern zu Beginn von Spaltendefinitionen umzugehen, empfiehlt es sich die CVs feldbasiert zu modellieren (keine InfoObjekte). Darüber hinaus muss der Calculation View entsprechend mit SQL-Privileges ausgestattet werden:
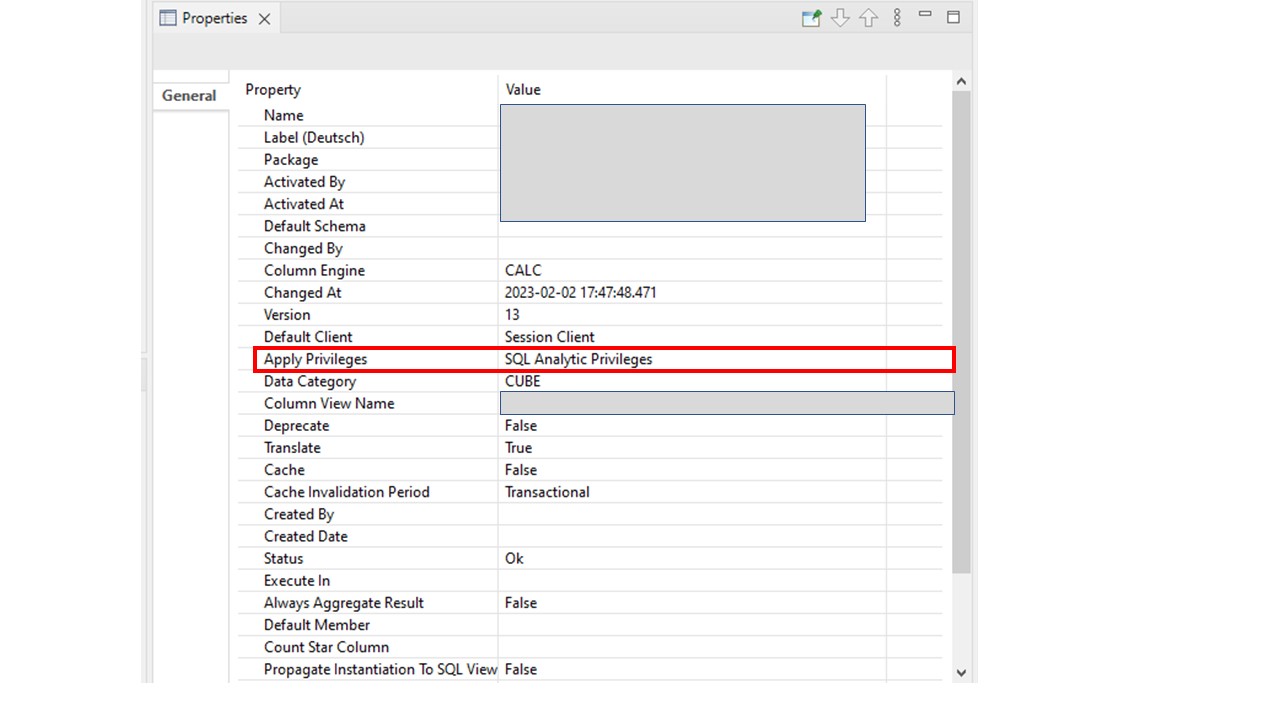
Die Vergabe der SQL-Privileges hat den Nachteil, dass der gleiche CV nicht über Queries oder andere BW-Objekte konsumiert werden kann. D.h. wenn das gleiche DataSet ein Mal für Abfragen aus der Cloud und ein Mal für SAP Queries (z.B. für Reporting) genutzt werden soll, benötigt es zwei CVs. Darüber hinaus musst du wissen, dass alle virtuellen Bestandteile des CVs (z.B. weitere CVs) ebenfalls mit SQL-Privileges ausgestattet werden müssen.
2. Daten zurück schreiben
Damit du die Daten zurück schreiben kannst, benötigt es eine einfache HANA-Tabelle, die wiederum im SAP BW mittels CVs konsumiert werden kann.
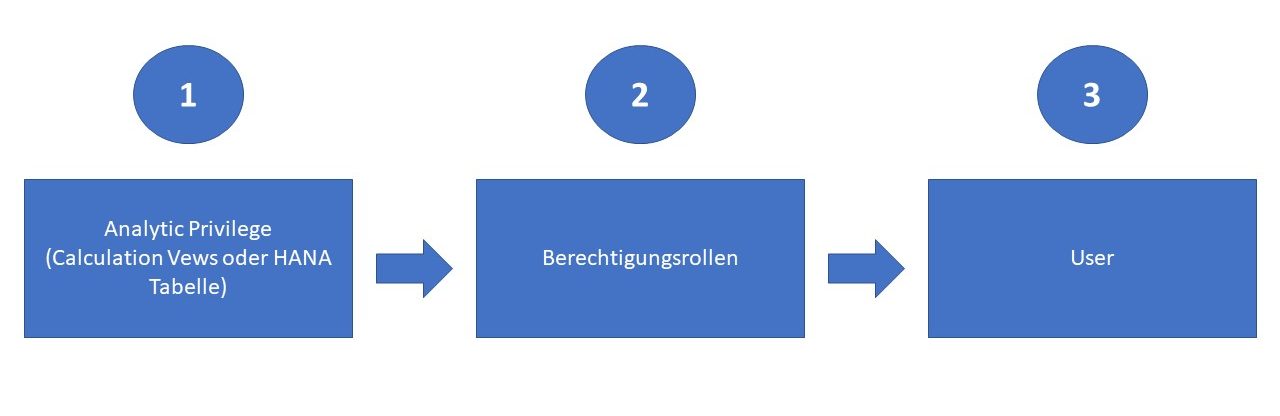
3. Berechtigungen für die HANA-DB einrichten
Der Schlüssel zum Erfolg in Projekten, die für komplexe Berechnungen SAP BW-Daten in der Cloud konsumieren möchten, liegt oft in den Berechtigungen. Je nach Governance in den Unternehmen startest du mit langatmigen Diskussionen mit der Group IT. Aus technischer Sicht benötigst du aber lediglich verschiedene Analytic Privileges, die dem User auf Basis eines Rollenkonzepts zugeordnet werden müssen. Das sieht wie folgt aus:
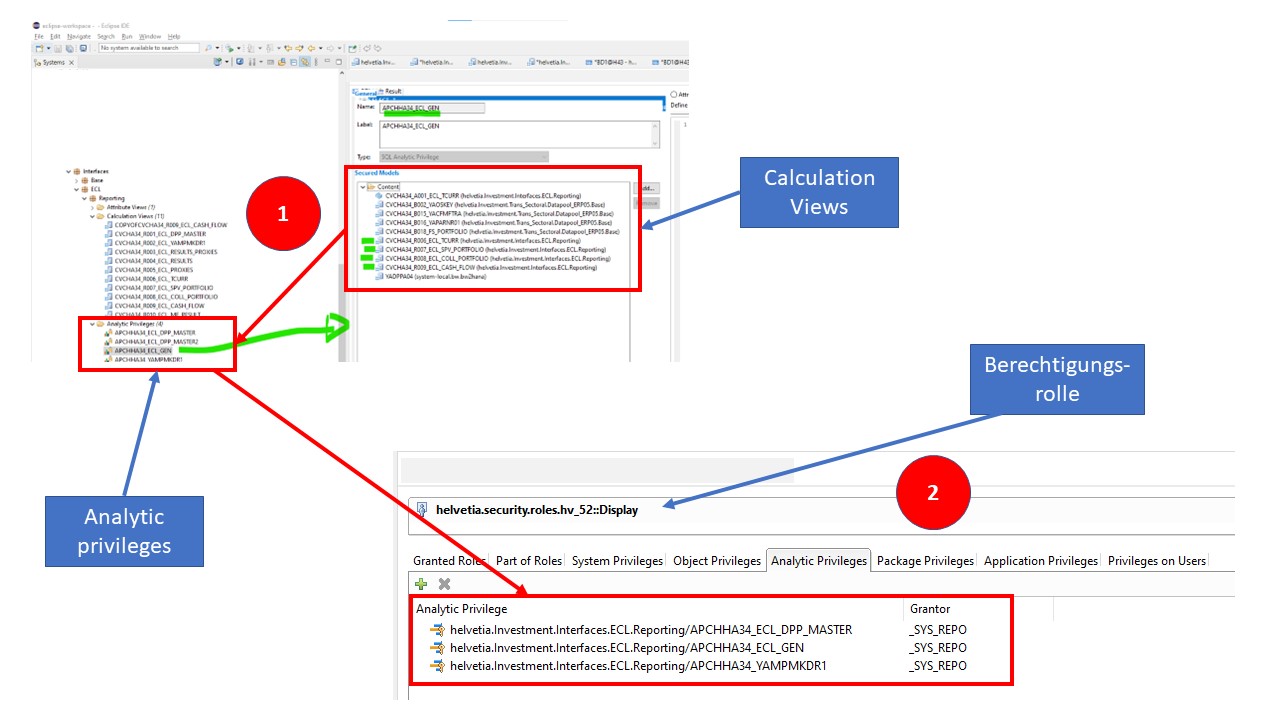
Die Analytic Privileges müssen eingerichtet werden. D.h. alle CVs, die innerhalb des Use Cases genutzt werden, werden in einer Analytic Privilege gesammelt. Empfehlenswert ist es für die Lese- und Schreibberechtigungen eigene Analytic Privileges und Rollen anzulegen, um die Berechtigungen für die einzelnen Objekte eindeutig ausprägen zu können.
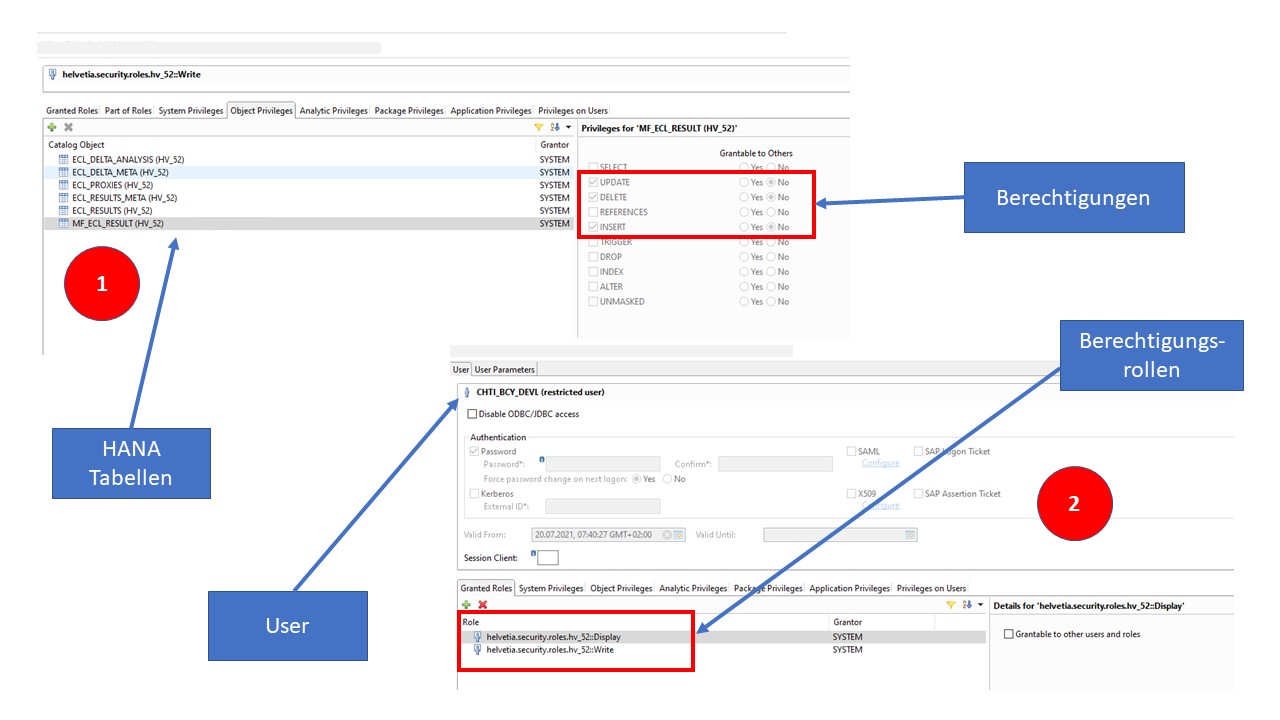
Anschliessend werden die Berechtigungen dem User zugeordnet, so dass über ein Python- oder R-Skript der entsprechende Zugriff erfolgen kann.
Key Take aways:
- Calculation Views mit SQL-Privileges ausstatten
- Falls etwas aus der Cloud in die HANA-DB zurückgeschrieben werden soll, eine entsprechende HANA-Tabelle anlegen
- Analytic Privileges und Rollen auf der HANA pflegen
- Rollen dem User zuordnen
- R-/Python-Skript entsprechend User, Host Name und Tenant mitgeben
Weiterführende Links zum Thema
How to create Analytical Privileges on HANA (I)
Tutorial: create Analytic Privileges in SAP HANA (II)
Check missing analytical privileges (onlay Classical Analytic Privileges)
Connecting python with SAP HANA system