Wenn dir einmal das Prinzip der Zeitreihe bekannt ist, wirst du merken, wie allgegenwärtig dieses Modell in unserem Alltag vertreten ist – die verflixte Zeitreihe ist überall – sei es bei Corona Fallzahlen, beim Bitcoinkurs oder bei Wetterinformationen. Der folgende Guide zeigt dir, wie du mit dem Datascience Tool KNIME Rohdaten aufarbeitest und in einer Zeitreihe darstellst.
Zuerst einmal einen kurzen Schritt zurück: Was ist eine Zeitreihe?
Als Zeitreihe wird eine zeitlich geordnete Folge von statistischen Messzahlen bezeichnet. Ein Beispiel einer Messzahl ist die Temperatur am Tag X. Die geordnete Abfolge von Tagestemperaturen ergibt eine Zeitreihe.
… und was ist eigentlich KNIME?
KNIME ist ein Datenanalyse Programm mit einem graphischen Interface. Mit sogenannten Nodes (Knoten) können Daten in einer Pipeline bereinigt, analysiert und visualisiert werden. KNIME ist Open Source und verfügt über unzählige Add-ons.
Wie bereite ich verschieden Datensätze auf eine Zeitreihenanalyse in KNIME vor?
Wir starten die Pipeline mit zwei „Reader Nodes“ (Abbildung 1: Node 1, 5) welche auf unsere CSV Rohdaten zugreifen. Mit den Nodes „Column Filter“ und „Row Filter“ führe ich bei beiden Datensätzen eine erste Bereinigung durch: Ungewollte Attribute (Node 2, 3) oder unvollständige Daten (7, 8) werden herausgefiltert. In einem nächsten Schritt kommt das Node „String to Date&Time“ (4, 9) zum Zug. Hier teilen wir KNIME mit, welche Spalten Datumsformate enthalten.
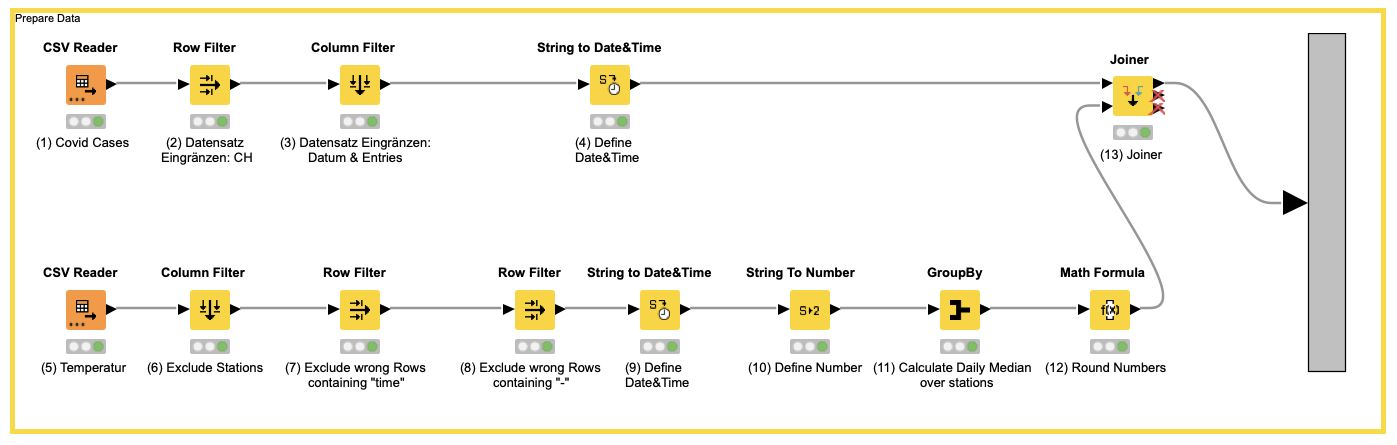
Da wir in der unteren Pipeline von Abbildung 1 verschiedene Messwerte von verschiedenen Stationen haben, müssen wir diese Messwerte mit dem „GroupBy“ (11) Node auf einen täglichen Time-Stamp gruppieren. In meinem Fall habe ich den Node (11) manuell konfiguriert und auch gleich den Median der Messwerte berechnet. Node (11) führt eine Kalkulation durch was bedingt, dass die Spalte Zahlen enthalten muss. Darum lagern wir vor Node (11) den Node „String to Number“ vor (10). Last but not least: Mit dem Node „Math Formula“ (12) runden wir den kalkulierten Medianwert auf eine Kommastelle.
Nun haben wir die Daten eingegrenzt, bereinigt und für die Zusammenführung vorbereitet. Der „Joiner“ (13) hilft mir nun die Daten auf einer Pipeline zusammenzuzuführen. Weiter geht es zur Normalisierung!
Warum ist das Normalisieren für Zeitreihen von Bedeutung?
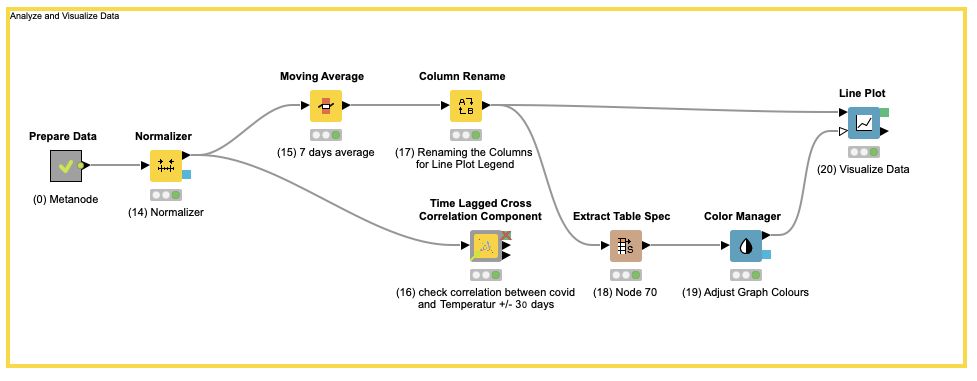
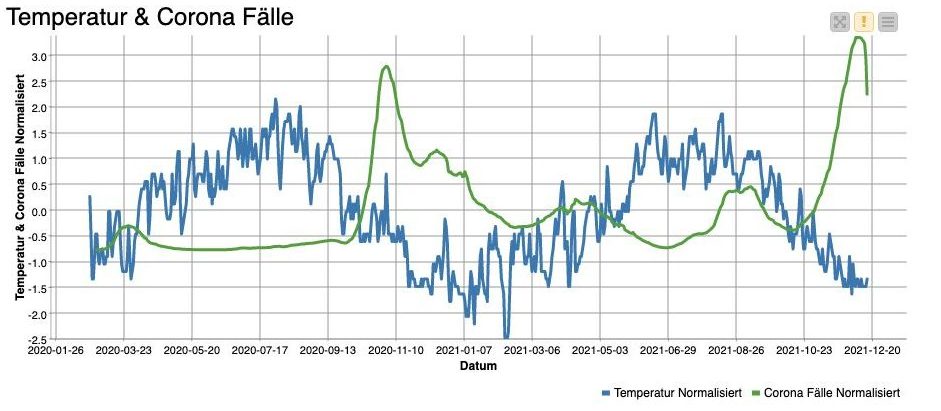
Durch den „Normalizer“ Node (14) werden Parameter auf eine einheitliche Skala normalisiert. Die Normalisierung ist von Bedeutung, weil damit unterschiedliche Paramater grafisch auf einer Zeitreihe dargestellt werden können (Beispiel Corona Fälle und Temperatur, Abbildung 3). Der „Normalizer“ lässt sich auf eine Z-Score Normalization (Gaussian) oder auf eine Min-Max Normalization konfigurieren.
Wie finde ich heraus, ob Datensätze miteinander korrelieren?
… durch den «TimeLagged Cross Correlation Component» Node (16) verschaffe ich mir einen Überblick, wie die verschiedenen Variablen miteinander korrelieren. In der Interactive View des Nodes kann man erkennen, auf welchem Lag die Korrelation am höchsten ist. Dieser „Lag“ ist später vor allem für Prediction-Modelle von Bedeutung.
Wie visualisiere ich Daten auf einer Zeitreihe?
Die Daten können nun in einem Line-Plot dargestellt werden „Line-Plot Node“ (20). Dabei ist es wichtig, die Column mit dem Time-Stamp der X-Achse zuzuordnen. Um die Visualisierung etwas aufzuwerten, kann die farbliche Darstellung über ein vorgelagertes Node «Colour Manager»(19) angepasst werden. Will man die Legende einer Achse ändern gilt, es ein „Column Rename“ (17) Node dem Line Plot vorzuschalten (20). Zusätzlich empfiehlt sich für die Darstellung in einem Line-Plot eine Glättung der Daten mit dem „Moving-Avarage“ Node.
Nun kommt der schönste Teil dieser Arbeit: „Execute-Pipeline“!
Fazit
Auf dem Weg von den Rohdaten zur Zeitreihe hat sich KNIME sehr gut geschlagen. Speziell für die ersten 17 Nodes lässt sich KNIME exzellent verwenden. Grosse Datensätze können einfach bereinigt und transformiert werden – ganz ohne den Einsatz eines komplizierten Statistik Programms. KNIME ist intuitiv und bemächtigt somit auch einen Hobby-Data-Scientisten zu grossen Taten. Was KNIME aber ganz klar nicht ist: Ein König im Visualisieren. Die Graphen wirken nicht frisch und haben keinen Dashboard Charakter. Hier lohnt sich wohl eine zusätzliche Schnittstelle zu einen professionellen BI-Tool wie Qlik, Power BI oder Tableau.
Weiterführende Links zum Thema
- https://www.youtube.com/watch?v=3rRQIbDChvM&ab_channel=KNIMETV
- https://hub.knime.com/knime/spaces/Examples/latest/02_ETL_Data_Manipulation/06_Date_and_Time_Manipulation/03_ETL_Energy_autocorr_stats~9pHnxeJUp8aueCJT
- https://hub.knime.com/knime/spaces/Education/latest/Learnathons/From_Raw_Data_To_Deployment/Learnathon/Challenges~Rgbkcgmdnvd5fC5l/