
Produktanbieter von Self-Service-BI-Tools vermitteln seit langem durch ihre Websites oder Tutorials, dass die neusten BI-Technologien so einfach zu nutzen seien, dass Anwender selbst ohne Beteiligung der IT-Abteilung BI-Anwendungen entwickeln könnten. Doch stimmt das? Ja und Nein.
Zwar ist es korrekt, dass die Nutzung von BI-Funktionen mit jeder neuen Generation von BI-Technologie für Anwender einfacher wird, ohne bei jeder Abfrage die IT konsultieren zu müssen. Dies ist jedoch nur der Fall, wenn es sich um ein einfaches und eindimensionales Modell handelt. Wird darüber hinaus eine bereichsübergreifende oder unternehmensweite Arbeit mit BI angestrebt, ist eine Auseinandersetzung mit gewissen Grundvoraussetzungen und Herausforderungen indes unumgänglich. Denn die Implementierung eines BI-Tools gestaltet sich meist nicht so trivial, wie häufig proklamiert wird.
Herausforderung #1: Organisation
Die Konzeption wie auch die Implementierung eines BI-Tools müssen ausreichend durchdacht und vorbereitet werden. Es müssen verschiedene Aspekte sowie Stakeholder miteinbezogen werden, um die Chancen einer erfolgreichen Implementierung zu wahren.
Es lohnt sich, ein klares Projektmanagement und -team sowie eine Roadmap zu erstellen, damit möglichst alle Erwartungen und Bedürfnisse der verschiedenen Stakeholder evaluiert werden können und weitere Themen wie Compliance (Wer hat welche Zugriffsrechte, auf welche Daten? usw.) vor der Realisierung mitberücksichtigt werden.
Im BI-Projektmanagement wird sich ebenfalls zeigen, dass nicht alle Eventualitäten von Anfang an mitberücksichtigt werden können, oder im Verlauf des Projektes neue Anforderungen dazukommen. Umso relevanter ist es, sich dieser Ausgangslage bewusst zu sein und diese «miteinzuplanen». Heute stehen mit den sogenannten agilen Entwicklungsmethoden (Bsp. Scrum) flexible, iterative Methoden zur Verfügung, die diesen Anforderungen Rechnung tragen.
Herausforderung #2: Daten/Infrastruktur/Technik
Für den Aufbau und die Funktionalität eines BI-Systems spielt die Qualität der Daten eine zentrale Rolle. Es ist von grundlegender Bedeutung, dass alle Anwender ihre Datenanalyse auf einer einheitlichen und validierten Datenbasis erstellen (Single Source of Truth).
Die Bereitstellung von zentralisierten Informationen lässt sich unter dem Begriff «Data Warehouse» zusammenfassen. Der Prozess der Datenintegration bis zur Datenbereitstellung lässt sich in vier Teilprozesse unterteilen, wie nachfolgend ersichtlich.
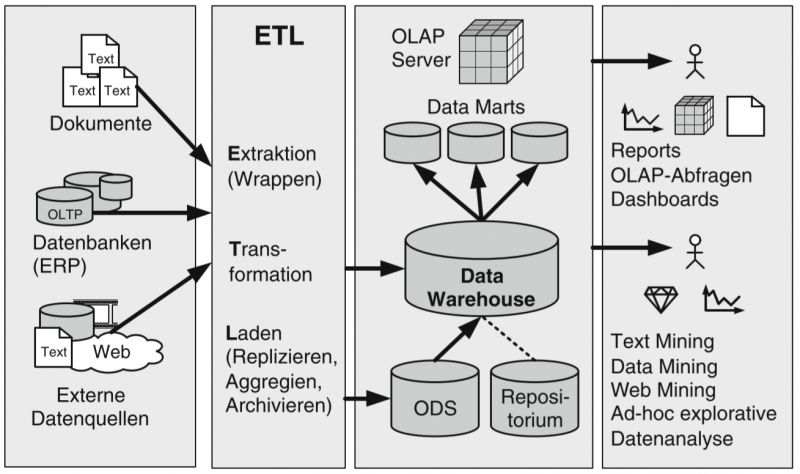
- Datensammlung
Datenquellen aus operativen Systemen sowie sonstige externe Daten können sehr unterschiedlich sein. Im ersten Schritt gilt es demnach, diese zu analysieren und anzubinden.
- Datenintegration
Die Datenintegration beschreibt den Prozess der Extraktion sowie Transformation und das konsistente Laden von Daten. Dem ETL-Prozess wird insbesondere im Hinblick auf die immer grösseren Datenmengen eine grosse Bedeutung zugesprochen.
- Datenspeicherung
Ziel der Speicherung ist es, die verschiedenen Quellen losgelöst von operativen Systemen an einer zentralen Stelle zu speichern und für die weiteren Prozesse bereitzuhalten.
- Datenanalyse
Das Datawarehouse stellt alle benötigten Informationen in aggregierter Form für die Datenanalyse durch Datenanalyse-Software-Anwendungen zur Verfügung.
Fazit
Die Herausforderungen einer professionellen Implementierung eines Self-Service-BI-Tools sind nicht zu unterschätzen. Dahingehend ist anzumerken, dass es sich, obwohl die Hauptaufgaben technischer Natur sind, nicht um ein rein technisches Projekt handelt. Ebenso relevant ist es, dass auch die verschiedenen Stakeholder involviert werden.