
Nicht immer sind alle entscheidungsrelevanten Daten auf den firmeneigenen Infrastrukturen vorhanden. Es kann auch Fälle geben in denen man sich Informationen extern aus den Tiefen des www beziehen muss. Hierfür gibt es geeignete Methoden und Tools die ihnen dabei Helfen können. In diesem Blog möchte ich ihnen eine dieser Methoden das sogenannte Webscraping anhand eines Beispiels näher erklären.
Szenario
Stellen sie sich das fiktive Szenario vor: Sie betreiben einen Onlineshop für Heimelektronikartikel und möchten sicher sein, dass sie ihre Produkte zu attraktiven Preisen am Markt anbieten. Ihr grösster Konkurrent ist der Onlineshop von Digitec, welcher am Markt mit täglich aktualisierten Preisen auftritt. Ihr Ziel ist es die Produkte zu gleichen Preisen anzubieten. Doch wie schaffen sie das?
Die Preise sind theoretisch alle auf der Homepage von Digitec ersichtlich, aber es ist ihnen aufgrund ihrer Firmengrösse nicht möglich jemanden anzustellen, der täglich die Produktpreise von Digitec analysiert. Doch es gibt eine Lösung die es ihnen ermöglicht automatisch nahezu jede beliebige Informationen aus dem Webshop zu extrahieren. Sie nennt sich Webscraping und kann beispielsweise mit der Programmiersprache Python sehr einfach und komfortabel betrieben werden. Wie das genau funktioniert erkläre ich ihnen im folgenden Artikel.
Beim webscraping geht es darum Informationen und Inhalte aus html-seiten zu extrahieren. In diesem Artikel beschränkte ich mich auf eine einfach Preisinformation. Mit genügend Erfahrung und Kenntnissen lassen sich aber unzählige Informationen extrahieren und man ist in der Lage sogenannte Bots oder auch Webcrawler zu programmieren, die vollautomatisch Webseiten durchforsten und Daten extrahieren.
Der folgende Artikel soll an einem einfachen Beispiel lediglich Möglichkeiten zur Nutzung aufzeigen und Neugierig auf das Thema Webscraping machen.
Vorbereitung
Zuerst einmal lohnt es sich einen Blick in diesen Artikel zu werfen bezüglich der rechtlichen Lage von Webscraping. Unser kleines Beispiel hier dient rein dem Forschungszweck. Wenn sie Webscraping aber produktiv einsetzen wollen, sollten sie sich mit den rechtlichen Gegebenheiten vertraut machen.
Unter Windows laden sie sich den Installer herunter und installieren sie Python auf ihrem Rechner. Vergessen sie den Neustart nach der Installation nicht ;-).
Anschliessend müssen wir noch beautifulsoup installieren. Auf Windows öffnen wir hierzu cmd.exe und geben pip install beautifulsoup4 ein.
Get your hands dirty
Nun wird es Zeit die Hände ein wenig schmutzig zu machen. Wir erstellen ein neues Pythonskript. Dazu öffnen wir einfach einen Texteditor und speichern ein File mit der Endung .py. z.b. digitec_scrapper.py.
Wie ist unsere Information in html eingebettet?
Als erstes besuchen wir die Produktseite auf Digitec um herauszufinden wie die Preisinformation im html code der Webseite verpackt ist. Wir interessieren uns z.B. für den Preis des iPhone 11 Pro. und gehen deshalb auf dessen Produktseite. Mit einem Rechtsklick auf den Preis bekommen wir ein Auswahlmenü mit verschiedenen Optionen. In Chrome wählen wir Untersuchen.
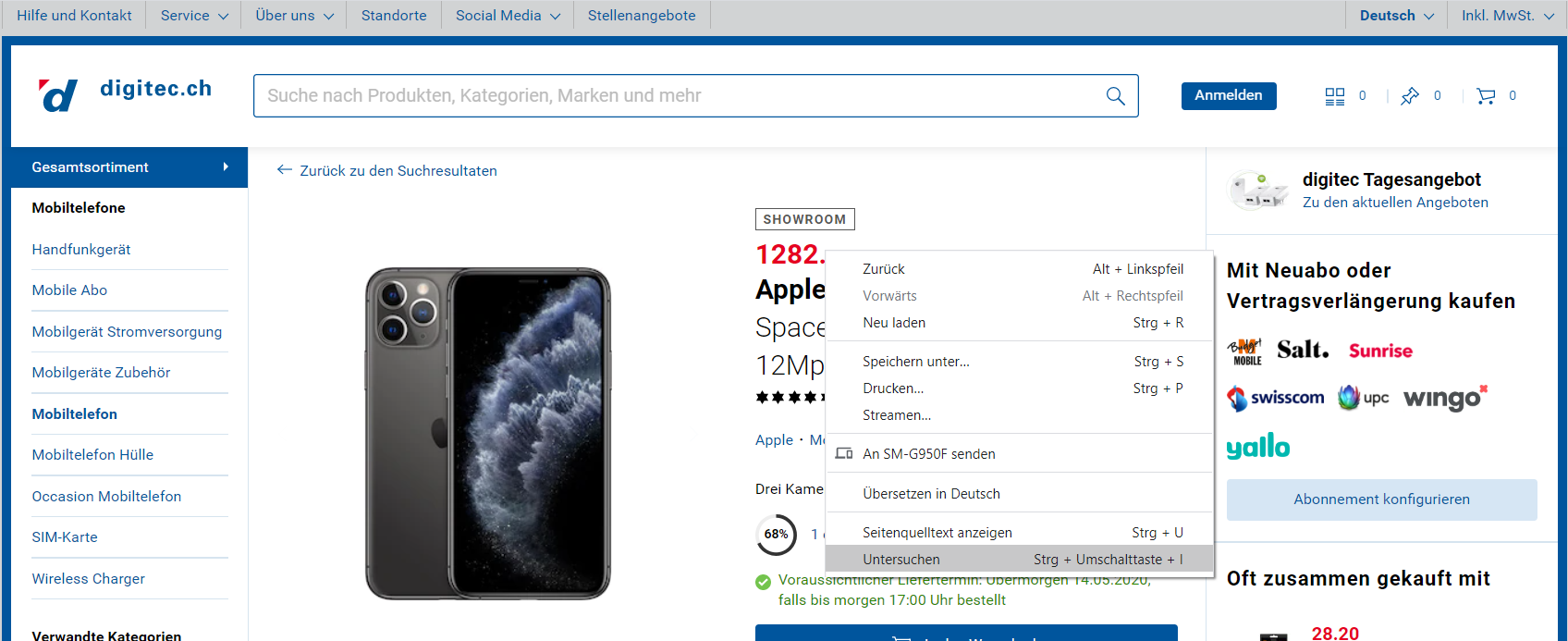
Nun öffnet sich in der rechten seite des Browsers eine Ansicht die den html Quelltext der Website anzeigt.
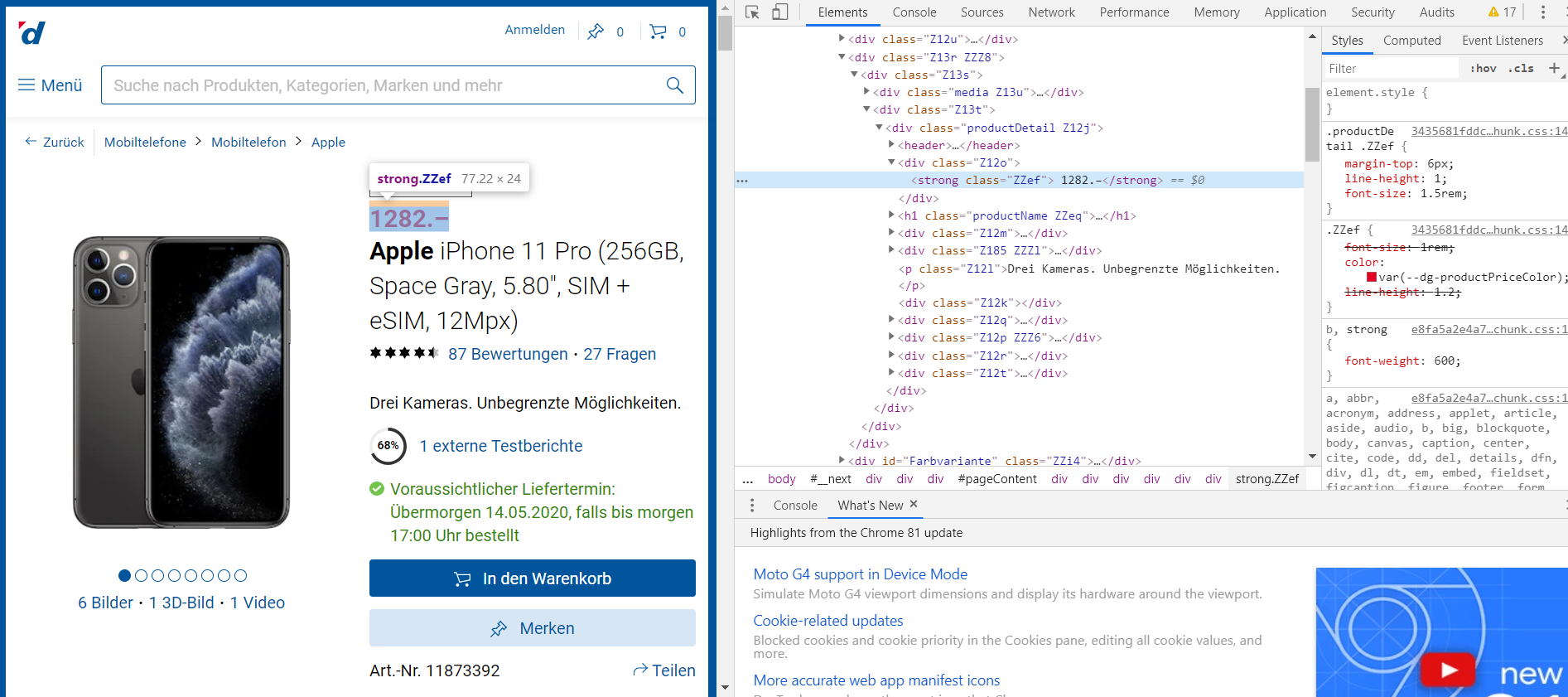
Wir können erkennen das unser Preis innerhalb eines sogenannten html tags steht:
<strong class="ZZef"> 1282.–</strong>
Codebeispiel
Unser Ziel wird es nun sein Code zu schreiben der gezielt nach diesem Tag auf der Seite sucht und die Text information extrahiert. In Python geht das mit beautifulsoup innerhalb von wenigen Codezeilen. Das Skript holt die Information und durckt sie anschliessend auf dem Bildschirm aus.
from bs4 import BeautifulSoup
import requests
URL = "https://www.digitec.ch/de/s1/product/11873392"
html_page = requests.get(URL)
soup = BeautifulSoup(html_page.content, 'html')
strong_tag = soup .find("strong", {"class": "ZZef"})
price = strong_tag.text
print(f"Preis: {price}")
Kopieren sie den obenstehenden Code digitec_scrapper.py und speichern sie die Datei. Anschliessend öffnen sie wieder cmd.exe und geben folgenden Befehl ein um das Skript auszuführen.
python C:\pfad\wo\das\skript\liegt\digitec_scrapper.py
Auf ihrem Bildschirm sollte nun Preis: 1282.- ausgegeben werden.
Codebeispiel im Detail
Zuerst importieren wir alle benötigen Libraries
from bs4 import BeautifulSoup
import requests
Dieser Schritt ist nur notwendig damit unserem Skript Funktionalität aus Beautifulsoup und requests zur Verfügung steht. D.h.
Aschliessend laden uns die html-seite herunter.
URL = "https://www.digitec.ch/de/s1/product/11873392"
html_page = requests.get(URL)
Danach wandeln wir die Seite in ein Beautifulsoup Objekt um auf dem wir diverse Funktionen ausführen können.
soup = BeautifulSoup(html_page.content, 'html')
da es in unserem Fall mehrere html-tags vom typ strong mit der class Z13t hat extrahieren wir zuerst das div tag in dem unser strong tag drin ist um auf Nummer sicher zu gehen.
div_tag = soup.find("div", {"class": "Z13t"})
danach können wir innerhalb dieses Tags letztendlich das strong tag extrahieren
strong_tag = div_tag.find("strong", {"class": "Zzef"})
wenn wir dann darauf das property text auswählen bekommen wir den eigentlichen Textinhalt des tags. In unserem fall ist das der Preis.
price = strong_tag.text
Nice to know
Wenn sie nun z.B. die Preis Informationen in einem csv File ablegen möchten kann ich ihnen diesen Blog empfehlen wo erklärt wird wie sie mit Python Information in ein csv ablegen können.
Wenn sie den ganzen Prozess automatisieren wollen, lohnt es sich einen Blick auf Azure Functions zu werfen. Mit Azure Functions können sie den Code den wir gerade geschrieben haben täglich automatisch in der Cloud laufen lassen. Sie können die Daten dann an ihre Firmeneigene Infrastruktur weiterleiten oder auch gleich Storage und/oder eine Datenbank in der Cloud aufsetzen.