Mit SQL Server 2005 wurden die Common Table Expressions (CTE) der Öffentlichkeit zur Verfügung gestellt, welche mit dem ANSI Standard SQL 99 spezifiziert wurden.
Seither kann man mit wenig Aufwand in wenigen Zeilen eine „Inline View“ erstellen, welche nur zur Laufzeit des Queries gültig ist und die weitere Syntax des Queries erheblich vereinfachen kann.
Eine solche „Inline View“ kann verwendet werden, um Beispiel Lookup Daten vorbereitet und / oder vorverdichtet in der Abfrage zur Verfügung zu stellen.
Doch was „kostet“ uns die Verwendung einer Common Table Expression im Vergleich zu einer entsprechenden Unterabfrage (sog Subquery)?
Was sind die Möglichkeiten, was die Unterschiede?
Ist alles, was mit einer CTE möglich ist, auch mit einer Unterabfrage lösbar? Wie sieht es umgekehrt aus?
Mit ein paar wenigen Tests wollen wir das hier mal beleuchten.
Damit werden wir die Beispiele erarbeiten
Entgegen der Gewohnheit des Schreibenden verwenden wir auch hier nicht ein Beispiel aus Microsofts „Spiel und Experimentier- Datenbank“ AdventureWorks, sondern Oracle’s althergebrachte Muster Tabellen „EMP“ und „DEPT“, welche aber in einer MS SQL Datenbank erstellt wurden. Dies vor allem auch aus Gründen der Einfachheit, da wir keine hochkomplexe Struktur benötigen, um die Grundzüge der verscheidenen Techniken zu erörtern. Allerdings werden wir im weiteren Verlauf der Beispiele nur die Tabelle EMP abfragen.
Die beiden Tabellen EMP und DEPT welche von Oracle seit den späten 90ern zur Schulung verwendet werden, repräsentieren eine Mitarbeitertabelle (EMP) und eine Abteilungstabelle (DEPT), mit welchem nahezu sämtliche Techniker in SQL geschult und auf übersichtliche und anschauliche Weise geschult werden können.
Der geneigte Leser, der sich mit diesen Tabellen auskennt, wird bemerken, dass vom Schreibenden ein neuer Mitarbeiter eingefügt wurden
Wir wollen ermitteln, ob es Unterschiede in der Verwendung der beiden im Titel genannte Query Techniken gibt, die über das optische hinaus gehen.
Die Analyse der Ausführungspläne wird nicht für andere RDBMS getätigt.
Common Table Expression – was bedeutet das eigentlich?
Mit dem ANSI Standard SQL 99 wurden die Common Table Expressions (CTE) eingeführt. Die Idee dahinter ist im Wesentlichen, eine einfache Methode zur Verfügung zu stellen, mit welcher man das Ergebnis einer Abfrage im weiteren Verlauf einer grösseren Abfrage auf einfache Art verwenden kann.
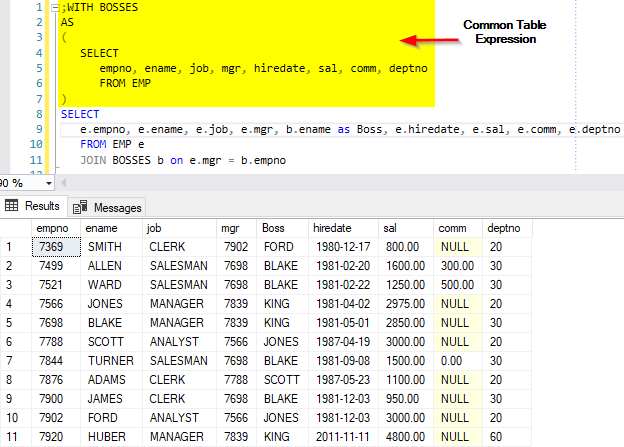
Der am häufigsten erreichte Effekt ist der, dass die eigentliche Abfrage an sich übersichtlicher wird, da die Unterabfrage (Subquery) wie eine Tabelle über einen Namen gejoined werden kann.
Verwendet man anstelle der CTE eine Unterabfrage muss man eben die ganze Unterabfrage in den Join eintragen und kann auf diese Weise das identische Resultat erreichen:

Query Optimizer
Die Frage stellt sich nun ein wenig, was sind den die Vor- und Nachteile der beiden Methoden?
Der Query Optimizer ist in jeder RDBMS dafür zuständig, die geschriebene Abfrage zu parsen und unter Zuhilfenahme der Datenbank das Ergebnis zurück zu liefern.
Natürlich führen auch für den Query Optimizer viele Wegen nach Rom, aber meist sind die schnellen Wege eher selten, also besteht sein Job darin, den „kürzesten“ (schnellsten) zum Ergebnis zu finden.
Wir werden die Ausführungspläne der verschiedenen Methoden dafür Vergleichen:
Der Ausführungsplan des Queries über die CTE sieht folgendermassen aus:
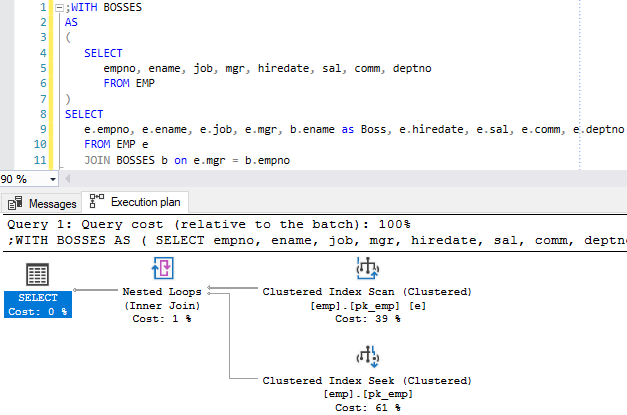
Der Ausführungsplan der Abfrage, die einen CTE konsumiertEs ist sehr schön zu sehen, dass die eigentliche Hauptabfrage von der Tabelle EMP mit dem Alias „e“ 39% des gesammten Aufwandes für die Lösung des Problems benötigt und die wiederkehrenen Zugriffe (Nested Loops) der CTE 61%. Die Nested Loops kommen zu stande aufgrund des (INNER) JOINs auf die CTE, welche für sich selbst auch eine Ergebnismenge darstellt.
Dahingegen sieht der Ausführungsplan der Abfrage über eine Unterabfrage wie folgt aus:
(Die Abfrage wurde bewusst im Printscreen festgehalten, um zu belegen, dass hier wirklich eine andere Abfrage ausgeführt und analysiert wurde)

Der Ausführungsplan der Abfrage mit Unterabfrage
So weit also noch kein Unterschied erkennbar. Auch hier nimmt die eigentliche Hauptabfrage auf die Tabelle EMP mit dem Alias „e“ 39% des gesammten Aufwandes in Anspruch, während dem die Unterabfragen durch die wiederholten Zugriffe über den (INNER) JOIN die restlichen 61% des Aufwandes verursachen.
Eine CTE als Hilfsmittel für eine hierarchische (rekursive) Abfrage
Interessant wird es, wenn wir in die CTE einen LoopBack einbauen, der auf die CTE selber zeigt; also eine Hierarchische Abfrage erstellen.
In diesem Zusammenhang sprechen wir von einer hierarchischen Abfrage, wenn wir eine rekursive Schleife über ein Attribut legen, welches innerhalb der Abfrage auf einen anderen Datensatz der gleichen Ergebnismenge zeigt. In unserem Beispiel ist dies die Spalte „mgr“, welche auf Spalte „empno“ der selben Tabelle zeigt und so auf dem Vorgesetzten referenziert.
Diese Rekursion folgt selbsttätig den Verlinkungen zwischen Vorgesetzem (mgr) und Mitarbeiter (empno) und steigt aus, sobald alle Rekursionen abgearbeitet sind. (vergleichbar mit dem rekursiven Durchsuchen eines Verzeichnisbaumes im Dateisystem eines Computersystems)
In unserem Beispiel ermitteln wir quasi das „Organigramm“ aus der einfachen Mitarbeiter Tabelle EMP, in dem wir den jeweiligen Vorgesetzten hinzumappen und die Ebene (Level) berechnen.
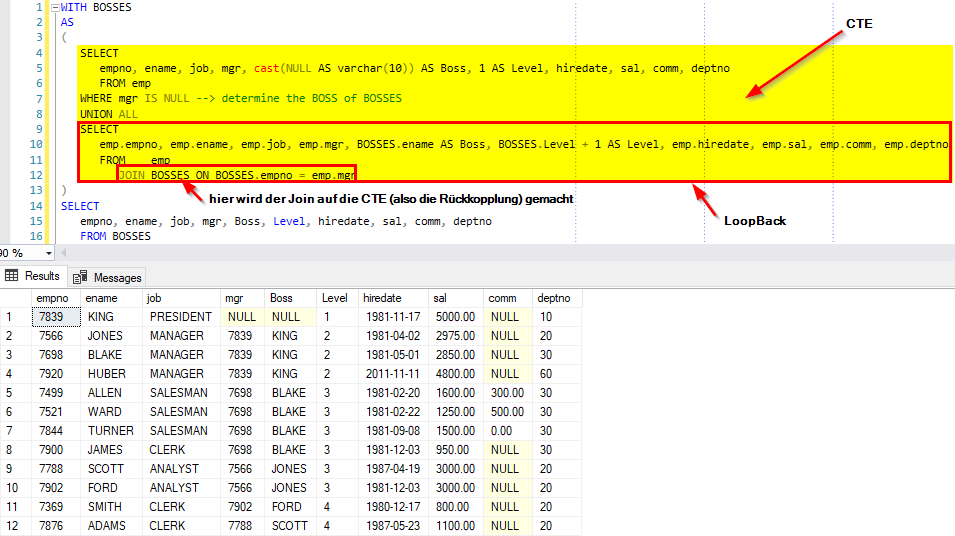
Ehrlicherweise muss hier noch erwähnt werden, dass man im Sinne einer stabilen Programmierung im Join der CTE eine „Notbremse“ einbauen sollte, welche die Spalte emp.Level auf 20 begrenzt, um bei Zirkularbezügen einen Ausweg zu haben, damit die Rekursion auch irgendwann auf eine Abbruchbedingung stösst.
Der Ausführungsplan für diese Abfrage sieht wie folgt aus:

der Ausführungsplan der hierarchischen CTE AbfrageDie Ausführungszeit liegt bei 0.08 – 0.12 Sekunden für die oben gezeigten elf Datensätze. (Dies wurde über mehrere Iterationen ermittelt, in dem diese Abfrage mehrfach hintereinander ausgeführt und die Zeiten notiert wurden)
In diesem Ausführungsplan ist ersichtlich, dass die Rekursion in den unteren Bereichen des Printscreens und die eigentliche Hauptabfrage in der obersten Zeile relativ ausgewogen die Ressourcen des RDBMS beanspruchen.
Wenn man das selbe Ergebnis mit einer „klassischen“ Abfrage unter Verwendung von Unterabfragen erreichen wird, muss man doch ein wenig mehr Aufwand betreiben.
Obwohl vieles versucht wurde, diese Art von Abfrage (hierarchische Abfrage) ist nur über einen Cursor, also programmatisch, oder dann über eine Unterabfrage je Hierarchie- Level lösbar.
Da wir in diesem Artikel aber über die Auswirkungen einer Unterabfrage auf den Ausführungsplan sprechen wollen, lassen wir die Lösung über den Cursor hier aussen vor:

Der Ausführungsplan für diese Abfrage zeigt sich dann ungleich komplexer, da jede dieser Unterabfragen einzeln ausgeführ werden muss:
(Die Farben im Ausführungsplan repräsentieren auch die entsprechenden Abschnitte der Abfrage)

Die Ausführungszeit liegt bei 0.1 – 0.25 Sekunden für die selben 11 Datensätze. (Dies wurde über mehrere Iterationen ermittelt, in dem diese Abfrage mehrfach hintereinander ausgeführt und die Zeiten notiert wurden)
Somit benötigt diese Variante zwischen 25% und 110% mehr Zeit in der Ausführung.
Es ist auch ersichtlich, dass die gleiche Ressource (die Tabelle EMP) nun nicht mehr nur zweimal im Ausführungsplan erwähnt wird, sondern zehn mal. Es wird auch für jede der Unterabfragen der einzelnen Ebenen die Abfrage separat aufbereitet und berechnet.
Dass dieser Ausführungsplan mehr Ressourcen „verbraucht“ als derjenige der rekursiven Abfrage ist schon rein optisch erkennbar.
Wie man sehr gut sehen kann, ist das nicht übersichtlich und vor allem: man muss schon zu Beginn genau wissen, wieviele Ebenen es geben wird, damit man ausreichend Unterabfragen für die Ebenen implementieren kann.
Darüber hinaus ist auch zu erwarten, dass bei steigender Datenmenge und steigender Anzahl an Ebenen die Ausführungszeit entsprechend zunimmt.
Fluch oder Segen? Sowohl als auch, der Kontext entscheidet!
Nüchtern betrachtet, hängt es vom Kontext ab, ob die Verwendung einer CTE einer Unterabfrage vorzuziehen ist.
In den meisten Fällen wird eine einfache Unterabfrage weder das Ergebnis, die Ausführungsgeschwindigkeit noch die Übersichtlichkeit beeinflussen.
Handelt es sich aber um eine umfangreichere Abfrage, wie sie in der Karriere des Schreibenden schon öfter vorgekommen ist, kann sich der Einsatz einer CTE durchaus lohnen.
Wenn man sich in Erinnerung ruft, dass die CTE wie eine Tabelle oder Sicht gejoined werden kann, wird die Verwendung der bereits schon komplexen Abfrage als Unterabfrage der Übersichtlichkeit nicht gerade zuträglich ist.
In umfangreicheren Abfragen mit erhöhtem Komplexitätsgrad können weitere Techniken zum Einsatz gebracht werden, welche zu einem späteren Zeitpunkt hier diskutiert werden.
Abschliessend kann man mit gutem Gewissen behaupten, dass die CTE Fluch UND Segen gleichzeitig sein kann, je nachdem, wie diese eingesetzt wird.
In jeder Abfrage sollten folgende Zielsetzungen immer vor Augen gehalten werden:
- Performance: vor allem bei Abfragen welche im Zusammenhang mit einem automatisierten Prozess verwendet werden
- Wartbartkeit: irgendwann wird es zu einer Anpassung kommen und dann ist
- Lesbarkeit ein entscheidender Faktor
Unter diesen Gesichtspunkten steht die Verwendung der Technik absolut im Hintergrund und sollte den übergeordneten Zielen untergeordnet werden.
Faustregeln
Als kleine Hilfestellung seien hier einige Punkte aufgelistet, welche als Faustregeln für die Verwendung einer (oder auch mehrerer) CTE sprechen können:
- Die eigentliche Abfrage ist relativ einfach und soll lesbar und übersichtlich bleiben.
- Die Unterabfrage kann über den Namen der CTE einfach identifiziert und deren Ergebnismenge bleibt innerhalb der Abfragen sprechend.
- Die Unterabfragen sind komplex, führen aber zu einer überschaubaren Ergebnismenge
- Die Unterabfragen sollen einfach zu ändern (leicht wartbar) sein.
- Man bevorzugt CTE’s
..und zu guter Letzt noch einige Punkte, welche für die Unterabfrage sprechen können.
- Die eigentlichen Abfrage ist relativ komplex während die Unterabfrage sehr übersichtlich ist.
- Die Unterabfrage wird sich kaum ändern
- Man möchte gerne in der Nähe der Spaltenauflistung in der Abfrage die Unterabfrage sehen.
- Man bevorzugt Unterabfragen in den JOINs
Oft braucht es ein paar Tests, wie sich die Verwendung der einen oder der anderen Technik auf den „Ressourcen Verbrauch“ auswirkt, aber dies ist ohnehin das tägliche Brot eines SQL Entwicklers.
Wie oben schon erwähnt gibt es Zielsetzungen, die über der Verwendung der einen oder anderen Technik stehen. Welche die beste ist, ist von Fall zu Fall unterschiedlich.
Oracle hat auch der „with“ CTE!
Ich muss Zeit finden um dein ganzes Blog zu lesen,
aber sieht sehr gut aus!