
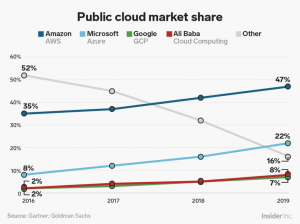
Everyone always wants to „move-up“ in the world. For over a decade now in the computer field that means moving up into cloud computing. The three biggest providers of cloud services are Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). AWS got a very good head start on the others when they made their services public in 2006. Even though Azure has had rapid growth in the past few years AWS still has almost half of the total cloud market share as the chart below shows:
For my own career growth I have decided to learn everything I can about what AWS has to offer. It is a very large computing ecosystem with many varied components to it. I will give a quick introduction into some of the building blocks AWS has to offer.
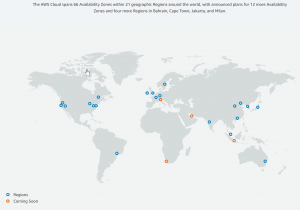
Regions and Availability Zones
One of the biggest advantages of cloud computing is being able to easily distribute your applications for performance, fault tolerance, and stability. AWS currently has 64 availability zones (i.e. distinct data centers) within 21 geographical regions. They have announced plans to add 12 more availability zones and 4 more regions.
Elastic Compute Cloud (EC2)
In its most simple form cloud computing is just a virtual machine in the cloud. You can use it just like any other server that you may connect to.
When you create an EC2 instance you will need to select the Amazon Machine Image (AMI) that you want. There is a long list of operating systems to choose from. Many different versions of MS Windows Server and just about every version Linux, e.g. Red Hat, SUSE, Ubuntu. Amazon even have their own optimized versions of Linux.
After the operating system is selected you will need to select an instance type. There is a long list of varying combinations of CPU, memory, storage, and networking capacity. It starts with a t2.nano instance that has one virtual CPU and 0.5GB of RAM and goes all the way up to a x1.32xlarge instance with 128 virtual CPUs and 1952 GB of RAM.
Simple Storage Services (S3 Buckets)
Amazon Simple Storage Services (S3) is an object storage service. Objects get stored as one file and can be downloaded and stored with up to 5 terabytes. The largest download size is limited to 5 gigabytes. An URL REST API is used for loading and accessing the file, so the data can be reached from anywhere in the world with an internet connection.
There are three storage classes of S3:
- Standard is for data that is frequently used and needs low latency and high throughput. It is used for dynamic websites, content distribution and big data workloads.
- Infrequent Access, as the name says it is meant for data that is not needed very often, but still needs to be quickly available when it is needed. It is used for backups, disaster recovery and long-term data storage.
- Glacier, again as the name says, it is like putting your data on ice. The retrieval rate can be selected to be minutes or up to hours
Of course the reason for the different storage classes is price. The faster the retrieval(e.g. Standard) the higher the price and the longer the retrieval (e.g. Glacier) the lower the price.
Lambda Serverless Computing
What is serverless computing? In serverless computing the application developer does not have to worry about the server resources where the application or service will run, they will only get loaded when they are triggered to run and the user will only get charged for the run time often measured in milliseconds.
This is an ideal option for smaller and fast running microservices. The small is beautiful approach. Instead of building large mammoth applications, smaller single event services can be built, and there is no need for a dedicated server to be standing by 24/7 waiting to run them. There are many types of triggers that can cause the application or service to run, e.g. a click on a web site, a change in a database or S3 bucket, a daily or hourly event etc.
In AWS the service to implement serverless computing is called Lambda.
Relational Database Services (RDS)
Normally when a database is needed a highly qualified database administrator (DBA) is also needed to install, configure, and then to maintain that database. With the Amazon Relational Database Service (RDS) there is no longer a need for a full time DBA. With just a few simple mouse clicks a novice user can have long list from different databases (Oracle, MS SQL-Server, PostgreSQL, Mysql, MongoDB, etc, etc) up and running. The developer can concentrate on developing the database and not have to worry about the infrastructure behind it. Backups, patches, and other service maintenance is all done for them automatically in the background.
Want to give it a try?
This was just a very quick and very simple introduction into just a very small subset of the services offered on AWS. There are many more services from machine learning, natural language processing, Internet of Things…… the list is very long and keeps growing very fast.
In my opinion Amazon AWS has the best trial period with 12 months for their Free Tier. Of course 120 CPUs with over a terabyte of RAM is not within the Free Tier (but you can pay for that, if that is what you want). The Free Tier instance uses t2.micro which is one virtual CPU and one gigabyte of RAM. That may sound small to the power hungry programmers, but remember small is beautiful and the price of free is very good.
Here is the link to get started with Amazon AWS cloud computing: