Auflisten oder „sauber joinen“? Eine Frage, die die Welt bewegt?
Es gibt mehrere Ansätze, ein SQL Query zu schreiben, welches über mehrere Tabellen Daten zusammenzieht.
Ein technisches „Richtig“ oder „Falsch“ gibt es nicht im eigentlichen Sinne, allerdings entbrennen hier oder da schon fast Glaubenskriege, wie ein sauberes Query auszusehen hat.
Nicht selten wird auch die Performance als Argument ins Feld geführt. Dazu kommen wir in einem späteren Blog.
Was ist denn der Unterschied?

Der eine Ansatz geht dahin, dass die als Datenquellen benötigten Tabellen in einer Liste nach dem „FROM“ Schlüsselwort aufgeführt werden:
Der zweite Ansatz verwendet das Schlüsselwort JOIN um anzuzeigen, dass die folgende Datenquelle mit der bereits erwähnten auf irgendeine Weise verknüpft werden soll:

Wo liegt denn das Problem?
In der Grössenordnung der oben gezeigten Queries sind auch optisch kaum Unterschiede auszumachen; das Komma wurde durch das Schlüsselwort JOIN ersetzt und die WHERE Klausel durch das Schlüsselwort ON.
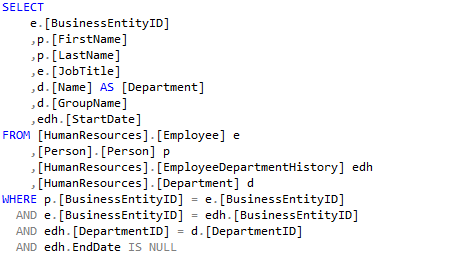
Etwas anders sieht es aus, wenn mehrere Tabellen verknüpft werden müssen, was in einem grösseren Datenmodell in der 3. Normalform (3NF) durchaus vorkommen kann:
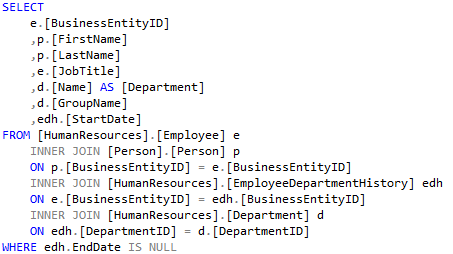
Nun kann man der Meinung sein, dass die Tabellenliste viel eleganter aussieht und mit viel weniger Text und Zeilen auskommt.
Das ist im Grundsatz nicht falsch, aber man sollte sich auch vergegenwärtigen, dass ein Query in seiner Lebensdauer sich verändert. Selten kommt es hier zu einer Reduktion in der Komplexität.
Wenn also noch weitere Datenquellen hinzukommen, vielleicht sogar nach dem Grundsatz, dass nicht zu jedem Datensatz der schon selektiert ist, ein Datensatz in der neuen Datenquelle stehen muss (LEFT JOIN oder RIGHT JOIN), dass wird es interessant und tendiert je nach Sauberkeit des Autors des Queries dazu, unübersichtlich zu werden.
Genauso umständlich, wie der vorangegangen Satz ist dann das Query zu lesen…
Ebenso wird es spätestens nach der zehnten eingebundenen Datenquelle fast ein Ding der Unmöglichkeit, noch auf einen Blick zu sehen, ob wirklich alle relevanten Verknüpfungen getätigt sind, damit es nicht zu einem kartesischen Produkt kommt.
Zum Dessert hier noch ein kleiner Vergleich, wenn zwei, drei LEFT JOINs mit einfliessen müssen.

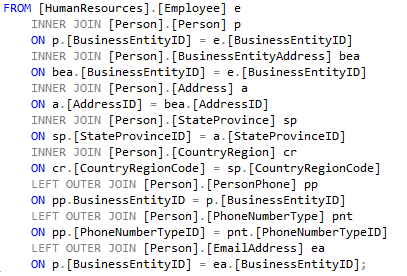
Es muss hierbei beachtet werden, dass aus syntaktischen Gründen (zumindest bei MS SQL Server) die LEFT JOINS bei den Tabellen angesiedelt werden müssen, mit denen sie verknüpft werden sollen, da ansonsten die entsprechenden Aliase nicht verfügbar sind. Wenn man also einen LEFT JOIN implementieren muss, bei dem mehr als nur gerade die vorangegangene Tabellen verknüpft werden soll, kommt man kaum um die Implementation einen (INNER) JOINS herum.
Konklusion
Da bei steigender Komplexität des Queries, insbesondere bei der Implementation von LEFT (OUTER) JOINs, es ohnehin gezwungenermassen zur Verwendung von (INNER) JOINs kommt, rate ich zur konsequenten Verwendung von „sauberen“ JOINs, da sich das Query bei einer späteren Anpassung einfacher liest und die JOIN Bedingungen direkt bei den entsprechenden verknüpften Datenquellen.
Im weiteren erreicht man auf diese Weise eine gewisse Einheitlichkeit im Coding und somit auch für dritte Personen, welche die Queries zu späteren Gelegenheiten warten müssen, eine verbesserte Lesbarkeit der Statements.