
Data Analytics als Teil von Big Data steckt heute in vielen Business Applikationen, mit denen Unternehmen ihr Geld verdienen. Frei verfügbare Programmier-Tools und eine riesige Data Science Community bieten Novizen schier unerschöpfliches Material, um mittels „copy ’n paste“ vermeintlich schnell und einfach eigene Daten-Anwendungen zu bauen. Daten sind das neue Gold – es herrscht wieder Goldgräberstimmung. Doch ist es wirklich so einfach?
Data Analytics ist ein schnell wachsender Markt. Prognosen sagen ein durchschnittliches jährliches Wachstum von ca. 30% und ein Marktvolumen von mehr als 70 Mrd. USD in 2023 voraus. Zum Vergleich: Die Gesamtleistung des Schweizer Bankensektors betrug in 2017 ca. 62.5 Mrd. USD.
In zahlreichen Industrien ist Data Analytics heute fester Bestandteil der Business Modell und wird teilweise als erfolgskritische Technologie eingestuft. Doch nicht nur Unternehmen profitieren von Data Analytics – auch Einzelpersonen erlangen Ruhm, Ehre und sicherlich einen attraktiven Gehaltscheck aufgrund von Data Analytics. So z.B. Nate Silver, amerikanischer Statistiker und Gründer sowie Chef-Redakteur des Blogs FiveThirtyEight.com, auf der er zu Politik, Sport und Wirtschaft schreibt – und zwar immer mit einem Bezug zu Daten und mit nachvollziehbaren Datenanalysen, die oft erstaunliche Einsichten ergeben.
Für Wahlprognosen vom Time Magazin gekürt

Nate Silver ist ein Data Native, nach dem Studium beim Wirtschaftsprüfer KPMG als Analyst tätig und schnell vom Job unbefriedigt, wendete er sich seiner Leidenschaft dem Baseball zu und studierte das Geschäft der Sportwetten. Mit seiner Datenaffinität und statistischen Ausbildung entwickelte er mit gewissem Erfolg Prognose-Modelle für die individuelle Performance von Baseballspielern. Richtig berühmt wurde Nate Silver mit seiner Vorhersage der US-amerikanischen Präsidentschaftswahlen 2008, deren Ergebnisse er in 49 der 50 korrekt vorhersagte. Quasi über Nacht wurde der damit zum Superstar der Wahlprognosen und durch das Time Magazin zu den 100 einflussreichsten Persönlichkeiten des Jahres 2009 gezählt. Noch etwas besser war sein Prognosemodell für die Präsidentschaftswahlen im Jahr 2012, deren Ausgang er in allen 50 Bundesstaaten korrekt vorhersagte.
Diese Leistungen brachten die New York Times dazu, seinen Blog gegen Lizenzgebühren in die politische Berichterstattung zu integrieren, was zu einem substanziellen Anstieg des Besuchertraffics auf der NYT Online-Präsenz führte. Auch andere Medienkonzerne haben sich für Nate Silver interessiert – mittlerweile gehört der Blog zu ABC News.
Die aufgeführten Beispiele zeigen – mit Data Analytics lässt sich gut Geld verdienen und berühmt wird man auch noch. Viele wollen es einem Nate Silver gleichtun. Daten sind das neue Gold – es herrscht Goldgräberstimmung.
Mit 7 Zeilen Code zum Data Scientist
Und die Zeiten könnten nicht besser sein. Leistungsfähige Analytics Tools wie R oder KNIME sind für jedermann frei verfügbar. Tausende Data Science Enthusiasten – die Community – postet Code für komplexe Machine Learning Anwendungen ins Internet, der mittels copy and paste und ohne Aufwand ins eigene Repertoire übernommen werden kann. Sieben Zeilen Code reichen aus, um ein neuronales Netz für Deep Learning zu bauen. Wie funktioniert so etwas?
Der Schlüssel sind fix fertige Funktionsbibliotheken oder Frameworks, die oft initial von Unternehmen entwickelt wurden und dann zur Weiterentwicklung der Open Source Community zur Verfügung gestellt werden. Im Beispiel des 7-Zeilen-Neuronalen-Netzes wurden das Framework TensorFlow und die Bibliothek tflearn verwendet. TensorFlow wurde ursprünglich von Google entwickelt und steckt als kommerzielle Variante in Google’s Produkten wie Gmail, Google Fotos oder Google Maps. 2017 wurde der Code unter Open Source Lizenz veröffentlicht. Seitdem haben knapp 2’000 Mitglieder der Open Source Community rund 50’000 Beiträge zur Weiterentwicklung von TensorFlow erbracht.
Mit wenigen Zeilen kopierten Codes zu performanten Data Analytics Anwendungen zu gelangen, scheint ein Kinderspiel zu sein und für jedermann erreichbar. Die Realität sieht jedoch anders aus. Zurück zu Nate Silver und seinen Wahlprognosen. Angespornt durch die beeindruckende Treffsicherheit der Wahlprognosen haben sich zwei Studienkollegen und ich Prognosemodelle als Thema unserer CAS-begleitenden Projektarbeit gewählt – ein paar Zeilen Code und ein paar Daten vom Bundesamt für Statistik – ganz einfach und für jedermann. Dachten wir. Los geht’s. Ein wenig Recherche und „Einlesen“ in zwei, drei Papers zu Prognosemodellen sollten uns den kick-start geben. Doch hier fing es an kompliziert zu werden. Je mehr wir lasen, desto umfangreicher wurden die Themenfelder, die zu berücksichtigen waren. Methoden wie Markov-Chain-Monte-Carlo Verfahren oder Gibbs Sampling hatten wir noch nie gehört, der Unterschied zwischen Frequentistischer und Bayes’scher Statistik war für uns völlig unklar und Formeln wie
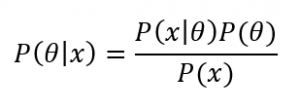 sahen plötzlich gar nicht „easy“ aus.
sahen plötzlich gar nicht „easy“ aus.
Es gehört schon eine Menge mehr dazu, um im Goldrausch des Daten-Zeitalters die dicken Nuggets auszugraben. Tools und Community können eine robuste mathematische und statistische Ausbildung nicht ersetzen. Waren früher mathematische Studiengänge nur für Nerds das Richtige, ist deren Popularität in den letzten Jahre stark gestiegen. In Zeiten der Digitalisierung ist auch ohne Prognosemodell vorherzusehen, dass der Bedarf an qualifizierten Data Scientists steigt. Die Auswertung von LinkedIn zu den begehrtesten Kompetenzen 2019 bestätigt dies. Vier der Top Ten Kompetenzen sind echte Goldgräber- ähm, Data Science Qualifikationen: Künstliche Intelligenz, Natural Language Processing, Scientific Computing und Data Science.
Fazit: Ja, Goldgräberstimmung herrscht und etliche Beispiele zeigen, dass sowohl Unternehmen als auch Einzelpersonen mit Data Science Gewinn erzielen und Berühmtheit erlangen. Eine fundierte Ausbildung ist für eine erfolgreiche Suche nach den Data Nuggets notwendig und lohnenswert. Data Science Qualifikationen gehören heute zu den Top Ten der gesuchten Skills.