Big Data ist mehr als ein Werbeschlagwort und bereits seit einigen Jahren bekannt und etabliert. Beim ersten Blick auf die aktuelle Tool- und Applikationslandschaft fühlte ich mich jedoch hilflos und von der Vielfalt und Unübersichtlichkeit schier erschlagen. Aber dem Tool Labyrinth kann abgeholfen werden.
Wenn man sich zum ersten Mal mit Big Data befasst wird man feststellen, dass dieses Schlagwort bereits überholt bzw. bereits in den normalen Sprachgebrauch übergegangen ist. Dies zeigt sich auch im bekannten Gartner Hype Cycle for Emerging Technologies wo ganz klar Schlagworte wie Artificial Intelligence AI oder Digitalisierte Ecosysteme z.B. Internet of Things IoT eine grössere Rolle spielen, obwohl diese auch als Teilmenge vom Big Data Oberbegriff gesehen werden können.
Einen guten Einstieg in das Thema was ist Big Data gibt folgendes Video:
Big Data ist also eine Sammlung von Daten? Nicht nur, Big Data hat einen Einfluss in vielen verschiedenen Bereichen der Informatik und umfasst eine schier unendliche Vielfalt. Aber die Daten sind das Herzstück oder anders ausgedrückt das neue Öl und die darin enthaltenen Informationen sogar das Gold der Zukunft. Dies beschreibt auch ein sehr guter Artikel, der im Online it-daily.net Portal im Februar 2018 erschienen ist. Diese Aussicht auf Profit ruft sehr viele IT Firmen, sowohl bereits etablierte Branchenprimi als auch Start Up’s auf den Plan und führt zu der extremen Vielfalt und Unübersichtlichkeit in der Applikationslandschaft.
Um dieses Tool-Labyrinth zu durchblicken hilft eine sehr gute und strukturierte Darstellung der aktuellen Tool-Landschaft, welche sehr schön in einem Blog Beitrag von Matt Turck – Managing Director at FirstMark in New York – vom Juni 2018 beschrieben ist.

Matt Turck – Big Data & Artificial Inteligence Landscape 2018Wenn man sich zum Vergleich die Landschaft von Matt aus seinem Beitrag „A chart of the big data ecosystem“ von 2012 ansieht, kann man die rasant wachsende Zunahme der Big Data Landschaft gut nachvollziehen.
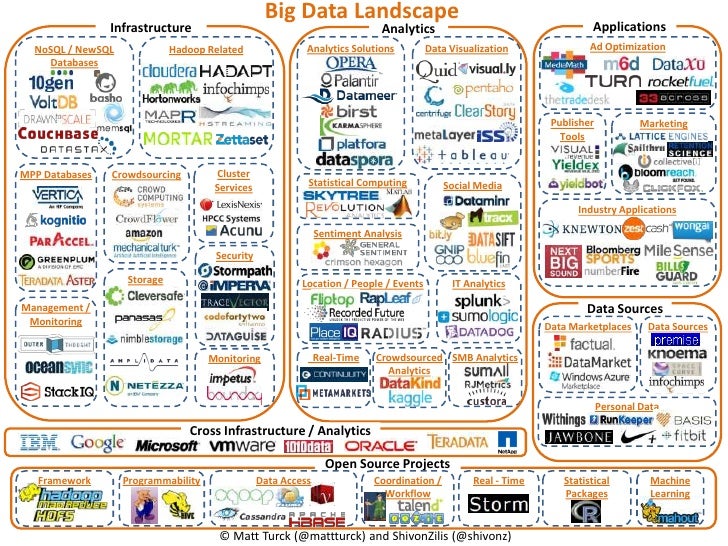
Doch auch bei Big Data bildet die Grundlage die Infrastruktur & Datenbank Landschaft
Wie bei jeder IT Implementierung bildet die Grundlage die Infrastruktur, ob physisch oder virtuell, ohne den Unterbau geht auch in der Big Data Welt nichts. Bereits im Plattform Bereich bewegt man sich mehr weg von On-Premises Infrastrukturen zu mehr Cloud Computing in den verschiedenen Abstufungen von Infrastruktur as a Service (IaaS), über Platform as a Service (PaaS) bis hin zu Software as a Service (SaaS).
Hier sind die grossen Global Player wie Google, Microsoft, Amazon und Oracle natürlich Vorreiter. Aber auch der grösste Anbieter im Chinesichen Raum Alibaba ist hier nicht zu vernachlässigen.
Dennoch ist vor allem im Bereich der Relationalen Datenbanken Oracle (DB Engines Ranking) immer noch führend auch wenn die Datenbank Landschaft (451 Research Übersicht) ähnlich rasant wächst wie die gesamte Big Data Tool Landschaft. Hierbei spielt vor allem der NoSQL Ansatz eine immer grössere Rolle. Die nicht relationale Darstellung der Daten in verteilten Systemen bietet neben der Möglichkeit von nur „Big“ zur Daten Vernetzung zu kommen. Dies beschreibt auch Stefen Kolmar in seinem Blog Beitrag „Datenbanken am Scheideweg“ bereits Anfang 2017 sehr gut. Hier sind die neuen Big Player auf der Applikationslandschaft Namen wie Cloudera, Hortonworks, MapR, Databricks und viele mehr.
Open Source als Motor?
In der oben aufgezeigten Grafik von Matt Turck ist auch die Vielzahl der Open Source Anbieter zu erkennen. Was hier ins Auge springt, ist dass sich die Open Source Angebote von der Infrastruktur über die Datenbanken sowie Anwendungs- und Analyse-Bereiche hinwegziehen. Dadurch bilden diese Open Source Applikationen die Grundlage für Innovation und Weiterentwicklung in allen Teilbereichen der Big Data Landschaft.
Diese offenen Zugangsmöglichkeiten bilden den Grundstock für eine grosse Informatik Big Data Community und ermöglichen auch Kleinbetrieben oder Start-Ups den Einstieg in diese Welt. Das Knowhow bzw. die Macht der Vielen in dieser stetig wachsenden Community ermöglichen einen schnellen Einstieg in die Thematik und einen rasantes vorwärtskommen. Eine gute Auswahl der Open Source Tools an denen im Big Data Umfeld kaum ein Weg vorbei führt beschreibt Vladimir Fedak in seinem Blog Beitrag „8 Open Source Big Data Tools to use in 2018“ vom August 2018.
Abschliessend kann ich für mich feststellen, dass ein zurechtfinden im Labyrinth, mit dem nötigen Interesse und etwas „Try & Error“, für alle die sich mit dem Thema auseinandersetzen wollen auch möglich sein sollte. Vor allem mit der Vielfalt der Open Source Anbieter bietet sich eine geeignete Spielwiese. Für mich war es ein Zusammenspiel aus dem Ablegen der ersten Berührungsängste und der Start mit den ersten Open Source Tools eine solide Grundlage. Einfache Suchbegriffe im Internet und die vielen Blog Beitrage zu den einzelnen Tools und Problemstellungen ermöglichen den Rest.