
KNIME ist das Werkzeug von dem der Datenanalyst träumt: Es ist kostenlos und lässt den Benutzer die Analyseaufgabe grafisch zusammenstellen und ausführen. Der Workflow kann dadurch den jeweiligen Ergebnissen einfach und schrittweise angepasst werden. KNIME bietet mehr als 3000 Bausteine und ist offen für die Integration von weiteren Programmiersprachen wie Java, R oder Python. Anhand von Twitter Daten wird in diesem Praxisbeispiel gezeigt, wie eine Textanalyse mit KNIME einfach und nachvollziehbar durchgeführt werden kann.
Im Rahmen unseres CAS Big Data Analytics kamen wir in den Genuss von zwei Tagen interaktivem KNIME Training. Die Installation ist zwar sehr einfach, da man nur das ZIP Entpacken muss. Durch die Grösse von 3.5 GB und fast 25’000 Dateien dauert es selbst mit modernen SSD’s einen Moment, bis das abgeschlossen ist. Mit einer Portion Geduld und Kaffeemaschine in der Nähe kann man das KNIME Paket downloaden, entpacken und dann loslegen.
Erste Schritte mit KNIME
Nach dem Starten präsentiert sich KNIME mit einer aufgeräumten Arbeitsumgebung, die man gerne ausprobiert.
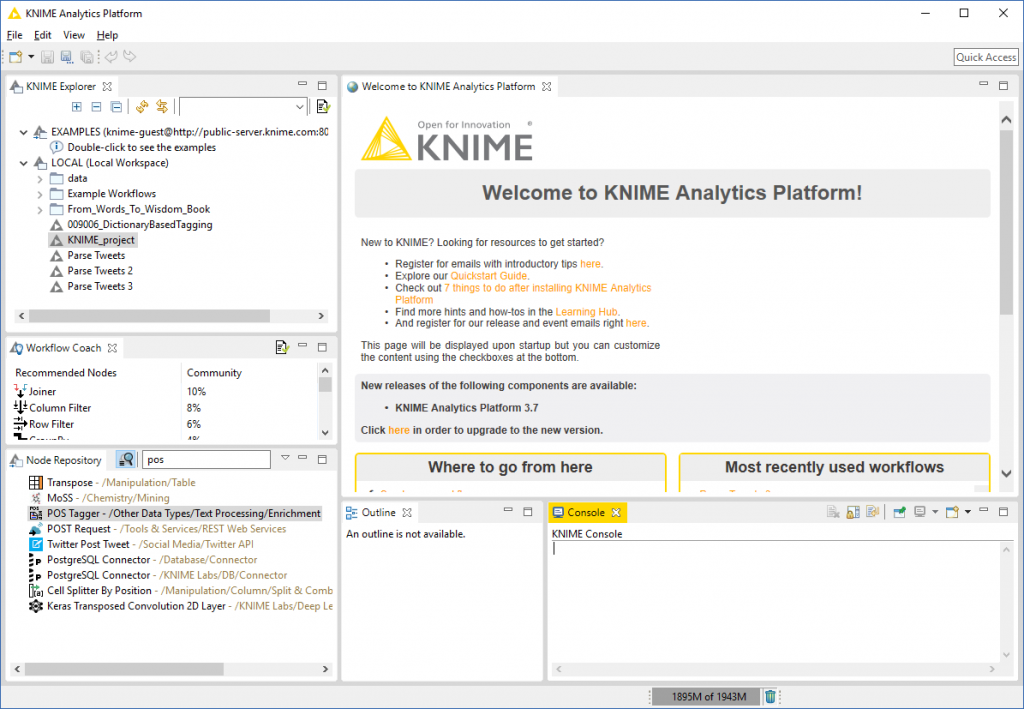
Am einfachsten geht die Arbeit mit KNIME mit einem bestehenden Workflow, den man dann anpassen kann. Für die Textanalyse verwenden wir das Webinar für die Sentiment-Analyse.
Das dazugehörige Beispiel findet man im Tool selbst oben Links im KNIME Explorer unter „EXAMPLES“ und navigiert dann zu folgendem Pfad:
08_Analytics_Types/01_Text_Processing/26_Sentiment_Analysis_Lexicon_Based_Approach
Textanalyse von Tweets als JSON Textdatei
Ausgangslage der Textanalyse sind die Twitter Daten, die wir bereits per Twitter API gesammelt und in einer Textdatei abgelegt haben. Die einzelnen Tweets im JSON Format sind mit Zeilenumbrüchen voneinander getrennt.

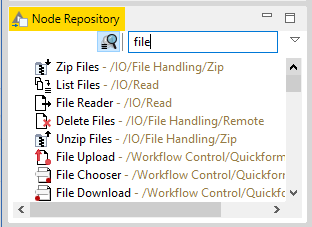
In KNIME funktioniert fast alles per Drag and Drop
An diese Eigenheit muss man sich erst ein bisschen gewöhnen. Also tippt man im Suchfeld des „Node Repositories“ erst mal „File“ ein und zieht danach den „File Reader“ auf die Arbeitsfläche eines neu erstellten Workflows.
Dasselbe Vorgehen verwenden wir für weitere Nodes, bis die Arbeitsoberfläche etwa so aussieht:
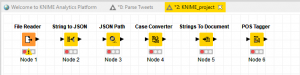
Der Pfeil auf der rechten Seite eines Nodes ist jeweils der Output, derjenige links der Input. Jetzt verbinden wir die Nodes wiederum per Drag und Drop miteinander, so dass ein Workflow entsteht.
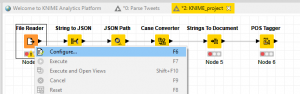
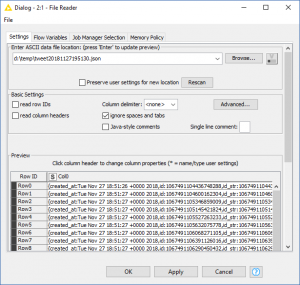
Mit der rechten Maustaste auf „File Reader“ klicken und „Configure…“ auswählen. Nach der Auswahl der Datei, zeigt KNIME bereits den Inhalt im unteren Bereich des Fensters an.
Wenn alles fertig konfiguriert ist, kann der Workflow gestartet werden über das Icon ![]() in der Toolbar. Jeder Node kann aber auch für sich ausgeführt werden. Dabei werden alle Abhängigen Vorgänger-Nodes ebenfalls ausgeführt. Das Ergebnis kann man sich durch integrierte Ansichten anzeigen lassen oder mittels spezieller Nodes in einem eigenen Fenster ausgeben. Dadurch ergeben sich kurze Entwicklungszyklen für den Workflow.
in der Toolbar. Jeder Node kann aber auch für sich ausgeführt werden. Dabei werden alle Abhängigen Vorgänger-Nodes ebenfalls ausgeführt. Das Ergebnis kann man sich durch integrierte Ansichten anzeigen lassen oder mittels spezieller Nodes in einem eigenen Fenster ausgeben. Dadurch ergeben sich kurze Entwicklungszyklen für den Workflow.
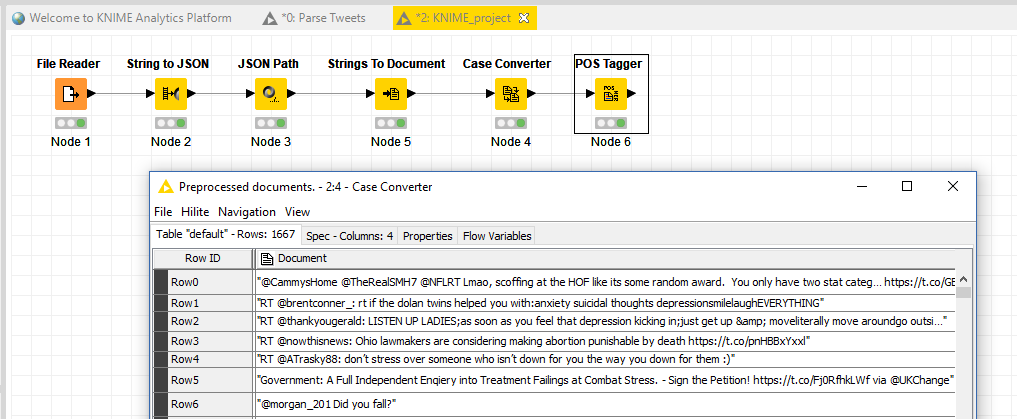
Die Nodes sind das Herzstück von KNIME
Nodes sind vorgefertigte Bausteine für bestimmte Aufgaben, die grafisch eingebunden und konfiguriert werden können. So gibt es Nodes für verschiedenste Aufgaben so wie
- Datenimport und Datenexport
- Datenbankanbindungen inklusive Big Data Technologien wie Hadoop, Spark oder HIVE
- Textanalyse mittels Natural Language Processing NLP
- Visuelle Ausgabe (z.B. Landkarten, Grafiken, Word Clouds)
- Machine Learning
- Mathematische Aufgaben
- Ausführung von Code in Java, R oder Python
- Schleifen und weitere Steuerelemente
- und vieles mehr
Nodes können in sogenannten Meta-Nodes zusammengefasst und als „Templates“ abgelegt werden. Diese „Templates„ kann man mit anderen Personen teilen und in weiteren Projekten verwenden. Die verfügbaren Nodes sind nebst lokalen „Node Repository“ auch im zentralen NodePit gelistet.
Mehr Informationen zu Machine Learning und Künstliche Intelligenz findet man in diesem KNIME Blogbeitrag. Auf der KNIME Website findet man sehr viel Information für Einsteiger und Profis von Datenanalyse mit KNIME.
Der vollständige Textanalyse Workflow
Unser Workflow wurde doch umfangreicher als anfänglich gedacht. KNIME ist dabei nicht zimperlich mit dem Speicher. Mit sehr grossen Datenmengen jenseits der 100’000 Tweets Marke pro Datei werden 16 GB RAM schon knapp. Als Umgehungslösung können Virtuelle Maschinen in der Cloud verwendet werden, die genügend Arbeitsspeicher bieten.
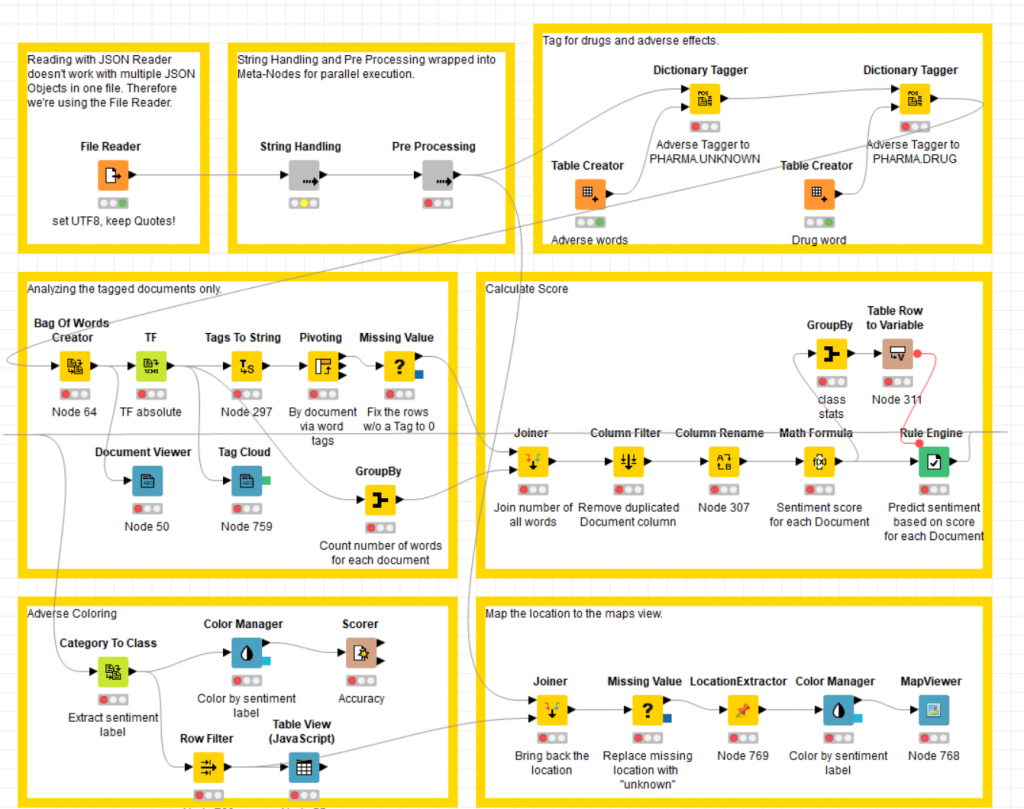
Der Workflow kann nun per Datei-Export und entsprechendem Import sehr einfach mit Kollegen geteilt werden. Nutzer des KNIME Servers können die Workflows und Meta-Nodes direkt teilen.
Fazit
Durch die einfache Bedienbarkeit, die Flexibilität und die enorme Auswahl an Nodes habe ich KNIME sehr schätzen gelernt als Tool zur Textanalyse. Schrittweise kommt man dem Ziel näher und bald hat man ein Modell, das auf weitere Daten angewendet werden kann. Ausserdem kann der Workflow einfach exportiert und auf einem leistungsstarken Rechner ausgeführt oder mit einem Kollegen geteilt werden. Auf jeden Fall bin ich sehr gespannt was noch in KNIME alles drinsteckt, denn ausgereizt habe ich das Tool noch lange nicht.