
Manuelle Aufwände reduzieren, Fehler minimieren und Zeit gewinnen stehen bei Document Understanding im Mittelpunkt. Wozu man es braucht, was es ist und wie man es mit fünf einfachen Schritten umsetzen kann.
Ob Rechnungen, Quittungen oder Bestellungen – in Unternehmen trifft man immer wieder auf ähnliche Dokumentarten, die man auswerten muss. Dabei verliert man viel Zeit und Effort um die Daten manuell aus den Dokumenten zu extrahieren. Mitarbeitende führen die eintönigen, zeitintensiven Tätigkeiten oft mit hoher Fehlerquote aus, da Konzentration und Aufmerksamkeit stark schwanken. Diese Aufgaben sind meist nicht anspruchsvoll. Fehler können trotzdem zu hohen Folgen führen, eine Null zu viel oder zu wenig, ein Wert falsch kopiert, eine Bestellposition vergessen und schon hat man eine ganze Reihe von Folgefehlern losgetreten. Ideale Tätigkeiten also, um sie an einen Roboter zu übergeben. Denn der Umgang mit Dokumenten ist eine zentrale Funktionalität aller RPA Tools.
Software Roboter lernen Dokumente zu verstehen
Kombiniert man RPA mit Document Processing und fügt noch etwas künstliche Intelligenz (KI) hinzu, erhält man als Resultat einen Document Understanding Roboter. Dieser ist in der Lage Inhalte aus Dokumenten automatisiert zu extrahieren, zu interpretieren und manuelle Tätigkeiten zu reduzieren. Der digitale Papierkram kann an den Roboter abdelegiert werden.
Klingt das nicht nach OCR (Optical Character Recognition)? Stimmt, aber es ist nicht dasselbe. Document Understanding ist nicht reines OCR. Denn mit OCR allein kriegt man keine Intelligenz aus Dokumenten. OCR macht Texte in gescannten Dokumenten nur lesbar. Mit Document Understanding hat man hingegen die Möglichkeit, die verschiedenen Dokumentarten zu erkennen, handgeschriebene oder abgedruckte Informationen, aber auch Checkboxen in einem Formular, PDFs und Bilder. Solche Informationen auszulesen und zu interpretieren ist die Idee von Document Understanding.
Und wie funktioniert das jetzt mit diesen fünf Schritten im Document Understanding?
- Schritt: Load taxonomy, die erwarteten Dokumenttypen und Felder werden definiert, ebenso welche Daten pro Dokumenttyp interpretiert werden sollen. Das heisst beispielsweise eine Rechnung mit Rechnungsnummer, Datum, Adresse usw.
- Schritt: Digitize, das Dokument muss digitalisiert werden, insofern es noch nicht erkennbar ist. Mithilfe von OCR Scanning wird erreicht, dass die Daten lesbar und interpretierbar sind.
- Schritt: Classify, dieser Prozess versucht das Dokument zu interpretieren und zu verstehen, worum es im Dokument geht, welcher Dokumenttyp vorliegt. Die Seiten eines mehrseitigen PDF Dokuments können dabei je nach Typ unterschiedlich verarbeitet werden. Nach der Klassifizierung kann man entscheiden, ob eine manuelle Validierung notwendig ist. Wenn die Engine beispielsweise nicht alle Elemente gefunden hat, muss ein Mensch ihr sagen, was sie richtig erkannt hat und was nicht. Diese manuelle Validierung hilft der Engine zu trainieren und zu lernen.
- Schritt: Extract, die Infos werden nach bestimmten Regeln extrahiert. Auch hier ist ein Validierungsschritt vorhanden, um das Modell zu trainieren.
- Schritt: Export, die Daten können in ein Datenmodell exportiert werden, dieses kann für die Automatisierung weitergenutzt werden.
Die fünf Schritte sind in der Regel immer dieselben, unabhängig von der genutzten Engine:
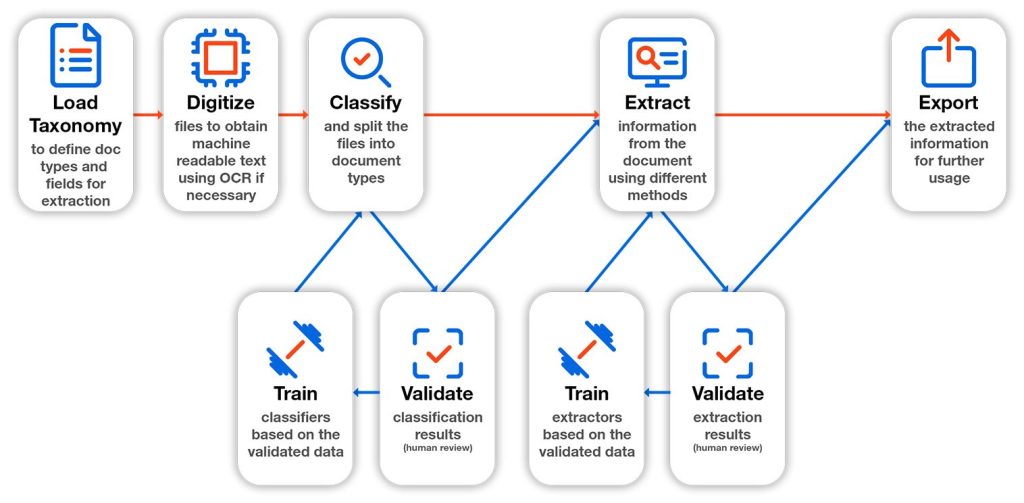
Und wo befindet sich die künstliche Intelligenz?
Die befindet sich im Schritt extract. Das Extrahieren kann RegEx basiert sein, man kann eine Regel erstellen, damit die Engine eine Checkbox in einem Formular findet oder Daten in einem Formular anhand eines Ankers ausmachen kann. Daneben kann man aber auch modellbasiert mit dem Machine Learning Extractor arbeiten. Dabei trainiert man ein Modell und teilt diesem mit, wenn du das vorfindest, gibt es hier eine Rechnungsnummer und hier einen Betrag usw. Diese Kombination aus regel- und modellbasiert ist der sogenannte hybrid approach (hybrider Ansatz).
Document Understanding mit UI Path
Das ganze Tooling in UI Path bietet eine flexible Möglichkeit, da es modular aufgebaut ist. Viele Elemente sind bereits vorkonfiguriert und programmiert. Ohne viel Programmieraufwand, lässt sich ein Document Understanding Roboter bauen. Eine Vielzahl von Templates, um mögliche Dokumenttypen zu erkennen, ist vorhanden. Diese kann man einsetzen und auf die verschiedenen Bedürfnisse adaptieren. Zudem bietet die Engine auch Machine Learning Skills, die sie befähigt selbstständig zu lernen.
UI Path beschränkt sich übrigens nicht auf die eigenen Activities, man kann auch auf andere Engines zurückgreifen wie Google, Microsoft, Kofax usw. und somit mit vortrainierten Modellen von anderen arbeiten.
Weiterführende Links: Wer gleich Lust hat das Ganze mit UI Path auszuprobieren, dem empfehle ich das Tutorial von Anders Jensen [https://www.youtube.com/watch?v=cp1hbChzUQ4]
images by gerd altmann at pixabay.com and uipath.com


