Welche Vorteile bringen Process Mining und Intelligent Document Processing für Unternehmen mit sich?
Die Digitalisierung schreitet weiter voran, jedoch gehören eine Vielzahl manueller und ineffizienter Prozesse zum Arbeitsalltag von vielen. In diesem Bericht werde ich die Bedeutung von Process Mining und Intelligent Document Processing aufzeigen.
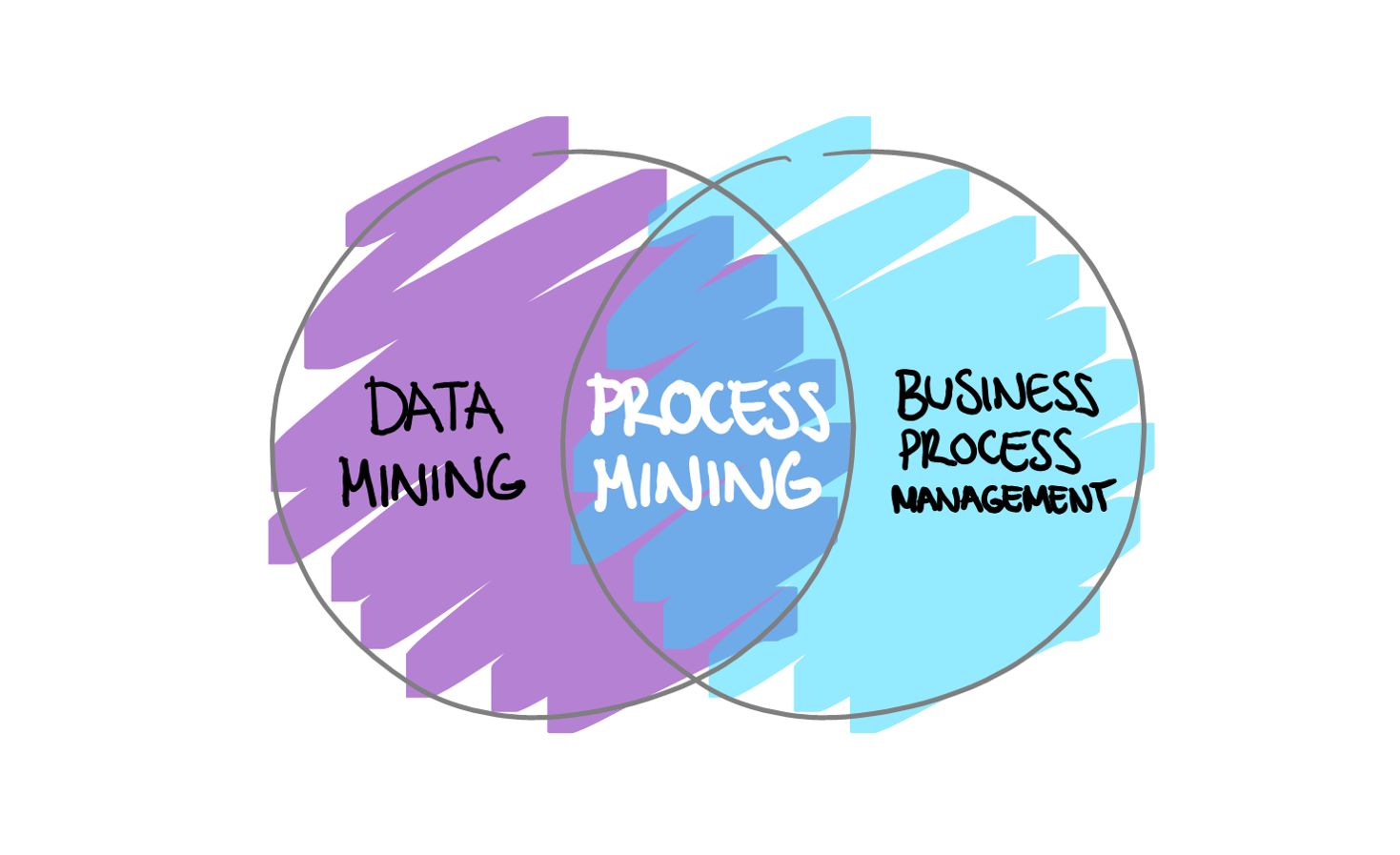
Was ist Process Mining?
Process Mining wendet Datenwissenschaft an, um Arbeitsabläufe zu validieren und zu verbessern. Durch die Kombination von Data Mining und Prozessanalyse können Unternehmen Protokolldaten aus ihren Informationssystemen auswerten. Dadurch wird ein tieferes Verständnis über die Leistung ihrer Prozesse vermittelt und Engpässe und andere verbesserungswürdige Bereiche aufgedeckt.
Mit Process mining werden Informationen in Form von Log Daten aus folgenden Systemen extrahiert:
- Customer Relationship Manager (CRM)
- Enterprise Resource Planning (ERP)
- Legacy Systeme
Aus den gewonnen Daten lassen sich hilfreiche Informationen über die untersuchten Prozesse gewinnen. Dauer, Effizienz und Hindernisse sind Aspekte die näher untersucht und optimiert werden können. Manuelle Prozesse können nicht berücksichtigt werden. Einzig digitalisierte Prozesse, bei welchen Log Daten entstehen, können analysiert werden. Damit ein Prozess unter Anwendung von Process mining analysiert werden kann, muss dieser weitere Voraussetzungen erfüllen (Aufzählung nicht abschliessend):
- Prozess muss innerhalb vom Unternehmen gut bekannt sein
- Prozess muss gut strukturiert und modelliert sein
- Jeder Prozessschritt lässt sich vom Informationssystem auslesen
- Grosse Datenmengen werden benötigt
Für die Gewinnung und Auswertung der benötigten Daten wird eine passende Process Mining Software benötigt. Diese liefern aussagekräftige Rückschlüsse zu den untersuchten Prozessen.
Was ist Intelligent Document Processing?
Intelligente Dokumentenverarbeitung (IDP) ist ein Technologiebereich, in dem Techniken der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML) eingesetzt werden. Dabei werden Informationen aus unstrukturierten oder halbstrukturierten Dokumenten extrahiert, klassifiziert und verarbeitet. IDP-Systeme können zur Automatisierung von Aufgaben wie Dokumentenklassifizierung, Datenextraktion und -validierung eingesetzt werden.
Strukturierte und unstrukturierte Daten
Strukturierte Daten sind in der Regel gut organisiert und strukturiert. Diese haben ein fixes Muster und können von ML-Algorithmen mühelos erkannt und analysiert werden. Die heutige Kommunikation findet oftmals über E-Mails, Fotos oder Text-Nachrichten, weshalb die Mehrheit der produzierten Daten unstrukturiert ist.
Unstrukturierten Daten können, gemäss IBM nicht mit herkömmlichen Daten-Tools und Methoden verarbeitet/analysiert werden. Diese Daten verfügen über kein vordefiniertes Datenmodell. Beispiele für unstrukturierte Daten sind: Social Media Posts, SMS, E-Mails
Vorteile von IDP
- Gesteigerte Effizienz: IDP-Systeme können Aufgaben wie Datenextraktion, -validierung und -klassifizierung automatisieren, was zu Effizienzsteigerungen und Kostensenkungen führen kann.
- Höhere Genauigkeit: IDP-Systeme nutzen KI und maschinelle Lernverfahren, um Informationen zu extrahieren, zu klassifizieren und zu verarbeiten, was zu höherer Genauigkeit führen kann.
- Geringere manuelle Arbeit: IDP-Systeme können sich wiederholende und zeitaufwändige Aufgaben automatisieren, wodurch der Bedarf an manueller Arbeit verringert werden kann.
- Verbesserte Datenqualität: IDP-Systeme können Daten bei der Extraktion validieren und standardisieren, was zu einer Verbesserung der Gesamtqualität der Daten beitragen kann.
- Erhöhte Skalierbarkeit: IDP-Systeme können eine grosse Menge an Dokumenten verarbeiten und erleichtern so die Skalierung von Prozessen.
IDP vs RPA vs OCR
IDP umfasst Optical Character Recognition (OCR) und Datenerfassungstechnologien, diese sind Teil eines grösseren Funktionsspektrums. OCR bildet einen wichtigen Teil von IDP in dem die Erkennung und Klassifizierung von Dokumenten ermöglicht wird. IDP ist keine robotergestützte Prozessautomatisierung (RPA). Sowohl RPA-Tools als auch OCR sind auf Aufgaben beschränkt, die keine Entscheidungsfindung auf hoher Ebene erfordern. Die grössten Unterschiede zwischen RPA, OCR und IDP liegen in der nativen Künstlichen Intelligenz (KI) und dem grundlegenden Verständnis von Dokumenten mit Kontextbewusstsein. Da IDP KI basiert ist, ist die Datenextraktion nicht an Regeln oder Vorlagen gebunden. IDP kann Dokumente lesen und aufgrund vom Inhalt menschenähnlich lernen. Um erfolgreich zu sein, muss IDP auf optimierte digitale Prozesse angewendet werden.
Weiterführende Informationen:
RPA (Robotic Process Automation)
Quellen:
What’s intelligent document processing (IDP)?


