
Wieso sich Elon Musk über DeepMind fürchtet und der beste GO-Spieler auf der Welt seine Karriere wegen Google’s Artificial Intelligence (AI) beendete.
Elon Musk sagte er fürchtet sich am meisten vor den Google AI Projekten von DeepMind.
«Just the nature of the AI that they’re building is one that crushes all humans at all games, I mean, it’s basically the plotline in ‚WarGames»
Elon Musk über DeepMind
Die Menschen unter euch, welche im Jahr 1997 bereits im jugendlichen Alter waren, mögen sich sicher noch an den historischen Sieg des Programms Deep Blue von IBM gegen den Schachweltmeister Garry Kasparov erinnern. Dieses Ereignis wurde weithin als Meilenstein von AI gesehen, jedoch war es nur für Schach nützlich. Dieser Blog möchte einen weiteren Meilenstein der künstlichen Intelligenz mit dem Brettspiel GO weiter erläutern.
Go Strategiespiel

Go ist ein Strategiespiel zwischen zwei Spielern, die abwechselnd „Steine“ auf ein 19×19 großes Brett legen. Das grundsätzliche Ziel des Brettspiels ist es mehr Territorium als der gegnerische Spieler zu umschliessen. Die Ursprünge gehen mehr als 2’500 Jahre zurück nach China. Schach wird als komplexes Spiel angesehen, aber nichts im Vergleich zu GO: Beim Schach liegen die möglichen Züge bei etwa 20, bei GO sind es über 200. Die Anzahl der möglichen Kombinationen auf dem Spielbrett ist grösser als die Anzahl der Gegenstände im gesamten Universum. Auch wenn wir alle Computer auf unserem Planeten nehmen würden und sie Millionen von Jahren rechnen lassen würden, würde die Rechenleistung nicht ausreichen, um alle möglichen Varianten zu berechnen.
![]() ,das Unternehmen, welches sich auf AI spezialisiert hat, wurde 2010 gegründet und im Jahr 2014 von Google übernommen. Das offizielle Unternehmensziel ist: „Solve Intelligence“.
,das Unternehmen, welches sich auf AI spezialisiert hat, wurde 2010 gegründet und im Jahr 2014 von Google übernommen. Das offizielle Unternehmensziel ist: „Solve Intelligence“.
AlphaGo – Supervised Learning
Im Jahr 2016 im DeepMind Challenge Spiel zwischen AlphaGo gegen Lee Sedol (18-facher GO-Weltmeister) konnte AlphaGo (die Software von DeepMind) vier von fünf Spielen gewinnen. AlphaGo war weder speziell auf den Kampf gegen Lee vorbereitet, noch sollte es gegen einen bestimmten menschlichen Spieler antreten. AlphaGo wurde trainiert mit einer detailiertem Analyse von über 100’000 professionellen Go-Spielen der Vergangenheit auf höchstem Niveau.
«I’m going to do my best to protect human intelligence»
Lee Sedol
Lee Sedol sagte noch vor dem entscheidendem Kampf, welcher auf der ganzen Welt live im TV zu sehen war, einen klaren „Erdrutschsieg“ voraus gegen den Computer und entschuldigte sich nach der Niederlage ei der südkoreanischen Öffentlichkeit. „Ich habe versagt“, sagte er nach dem Turnier vor den Medien. Im letzten der fünf Spiele konnte er schliesslich einen Sieg einfahren. Er geht in die Geschichte ein als der einzige Mensch der AlphaGo in einem offiziellen Turnier schlagen konnte. Die AlphaGo Software, welche Lee Sedol besiegte, arbeitet mit Hilfe mehrerer neuronaler Netzwerke, deren Computer 48 Tensor Processing Units (TPUs) benötigten – spezialisierte Mikrochips.
AlphaGoZero – Reinforcement Learning
Ohne vorherige Spieldaten oder menschlichen Unterricht liess das System Millionen von Spielsimulationen gegen sich selbst laufen, um das Spiel zu erlernen und den Algorithmus zu trainieren. Diese Technik ist leistungsfähiger als frühere Versionen von AlphaGo, weil sie nicht mehr durch die Grenzen des menschlichen Wissens eingeschränkt ist. Nach nur 40 Tagen lernte die Software das Spiel von Grund auf und war in der Lage, den besten Go-Spieler der Welt zu werden. Es gewann gegen Alpha Go Lee, die Software welche zuvor Lee Sedol besiegte, deutlich mit 100:0. AlphaGoZero verwendet «reinforcement learning” und kein “supervised learning”.Am Training von AlphaGo Zero waren vier TPUs und ein einziges neuronales Netzwerk beteiligt, das zunächst nichts über Go wusste.
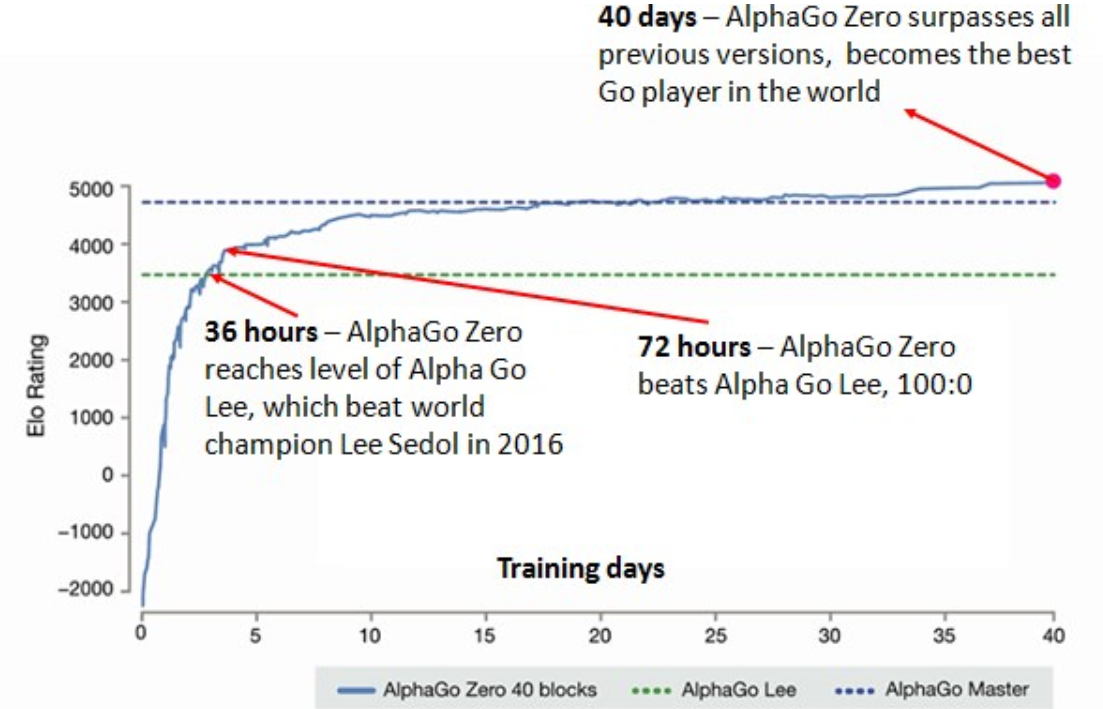
Am ersten Tag des Trainings spielte AlphaGoZero(AGZ) nur zufällig und unberechenbar. Wie ein Kleinkind, dass planlos Steine auf dem Brett verteilen. Aber bereits nach drei Tagen Selbsttraining war es in der Lage, die AlphaGo Version zu übertreffen, welche gegen Lee Sedol gewann.
Beim maschinellen Lernen geht es um große Daten und Leistung. Aber wie wir bei AlphaGo Zero sehen, ist der Algorithmus viel wichtiger als große Daten und Computerleistung. AlphaGo Zero verbrauchte viel weniger Computerleistung als die vorherigen Versionen.
AlphaZero – Eine generalistische Version
AlphaZero (AZ) ist die neuste Software (2017) des DeepMind Teams. Die Idee dahinter ist, einen Algorithmus zu erstellen, der für mehrere Spiele verwendet werden kann: Schach, Shogi (Japanisches-Schach) und Go. Nach nur 4 Stunden Training war AZ in der Lage, die beste Schach Engine der Welt zu übertreffen. Interessant ist die Tatsache, dass AZ nur 80’000 Positionen pro Sekunde suchte, im Vergleich zu Stockfish mit 70 Millionen. Alpha Zero kompensiert die geringere Anzahl an Auswertungen und Suchabfragen, indem es sein eigenes tiefes neurales Netzwerk verwendet und sich nur auf die vielversprechendsten Varianten zu konzentrieren. Im japanischen Schachspiel Shogi, übertraf AZ Elma bereits nach 2 Stunden Spielzeit. Bei Go dauerte es 34 Stunden Selbstlernens, bis AGZ in 60 von 100 Spielen besiegte.
Schlusswort
Gerade der Erfolg von AlphaGoZero (AGZ) kann als einer der grössten Meilensteine in der Entwicklung von AI angesehen werden. In der Vergangenheit gab es die weit verbreitete Ansicht, dass Big Data und riesige Rechnerleistungen der Schlüssel zum Erfolg für AI sind. AGZ lernet ohne jegliche historischen Daten und wurde innerhalb von 40 Tagen der beste GO-Spieler der Welt. Alpha Zero schaffte das später sogar in 34 Stunden. Lee Sedol trat 2019 vom Professionellen GO Sport zurück, mit der Begründung, dass AI nicht schlagbar ist. Doch ist dies eine Niederlage für die Menschheit? NEIN, aus meiner Sicht ist eher das Gegenteil der Fall. Dank AI wurden das Spiel neu entschlüsselt, viele GO Theorien die seit Hunderten von Jahren als effizient angesehen wurden, stellten sich als nicht optimal heraus. Und es wurden neue Strategien entwickelt, somit Spielen nun auch die Besten Go Spieler der Gegenwart auf einem höheren Level.
Ich kann den öffentlich zugänglichen Film „AlphaGo – The Movie“ sehr empfehlen, um mehr über die Entwicklung und den historischen Erfolg der Software AlphaGo gegen den Weltmeister Lee Sedol in Seoul im Jahr 2016 zu erfahren:
Weiterführende Beiträge:


